Yellowfin 選定ガイド
Yellowfinは、エンタープライズアナリティクス、および組み込みアナリティクス両方のユースケースで使用され、独自のアナリティクスアプリケーションを構築します。本ガイドを活用することで、Yellowfinが要件に対して技術的に最適であるかどうかを確認できます。

アーキテクチャー概要
-
アーキテクチャー概要
Yellowfin アーキテクチャーの主要なコンポーネントは何ですか?
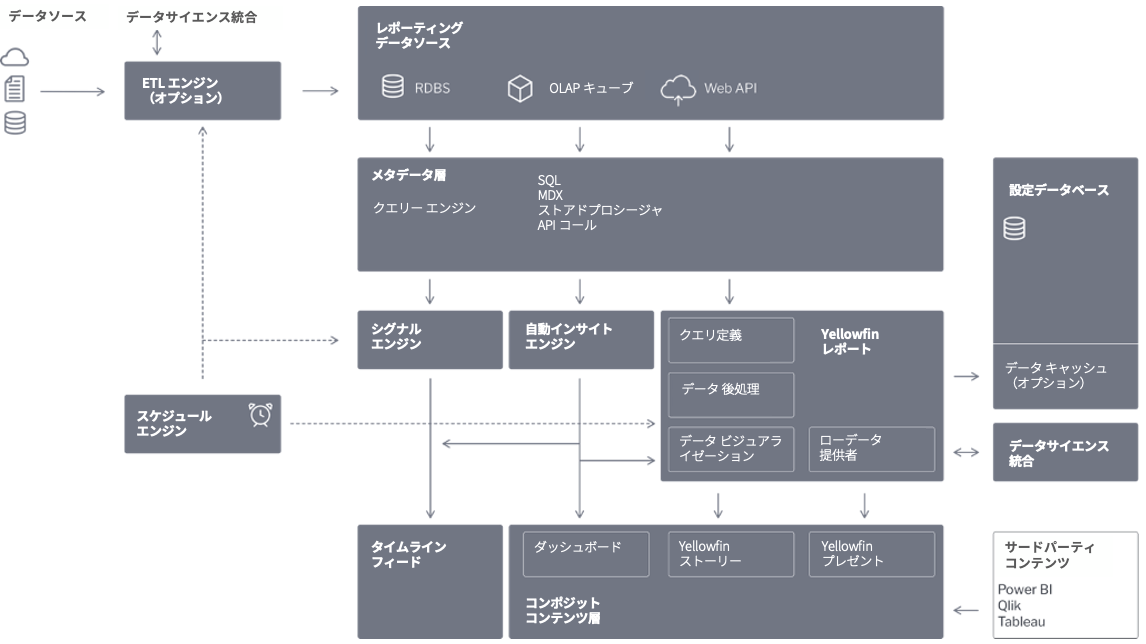
以下に、Yellowfin アーキテクチャーの主要な機能コンポーネントについて説明します。
構成データベース:Yellowfinで作成されたユーザー、セキュリティ、データソース、コンテンツに関する情報など、Yellowfinで必要なすべての構成データを保存します。作成されるコンテンツには、レポート、グラフ、ダッシュボード、プレゼンテーション、ストーリーの定義が含まれます。SQL Server、MySQL、Oracleなど、様々なリレーショナルデータベースに実装できます。
レポート作成データソース:Yellowfinは、最も一般的なリレーショナルおよび非リレーショナルデータベース(適切なJDBCドライバーを使用)、キューブ(MDX経由)、フラットファイル、APIエンドポイント(一般的なクラウドアプリケーションに接続するすぐに使用できるコネクターを含む)を含む、幅広い範囲のデータソースにライブ接続できます。このフレームワークは拡張可能であり、顧客は独自の接続を作成することも、利用可能な場合は、サードパーティ接続を使用することもできます。
ETL エンジン(オプション):これは、ユーザーがデータを分析に適した形式にさらに変換する必要がある場合に利用できるオプションコンポーネントです。データはどのようなソースからでも読み込むことができ、結合し、変換した後に、Yellowfinがサポートする書き込み可能なDBMSに書き戻すことができます。データのマージや分割、新しいカラム(列)の作成やデータ型の変換、値の置換など、様々なトランスフォーメーションステップを使用できます。さらに、ETLワークフローをサードパーティ製のデータサイエンスモデルに接続することで、予測アルゴリズムの結果を使用してデータを拡張することもできます。現在、YellowfinはPMML形式でエクスポートされたモデルと、Rサーバ、H2O.ai、AWS SegaMakerへのライブ接続をサポートしています。ETLステップフレームワークは拡張可能であり、顧客は独自のカスタムETLステップを構築し、プラグインできます。
メタデータレイヤー:このレイヤーは、レポートの作成元になるデータに関する必要な情報をすべて含みます。これにはテーブル構造、結合条件、計算フィールド、データ書式などが含まれます。このデータはSQL、MDX、またはライブデータ接続に動的にクエリーを発行するその他の呼び出しの形式で、DB固有のクエリーを生成するクエリーエンジンによって使用されます。データはストアドプロシージャ、またはハンドコーディングSQLから取得することもできます。セキュリティの側面は、マルチテナント環境でのデータの論理的、または物理的な分離をサポートするために、アクセスフィルターや、データソース置換など、このレベルで適用されます。
Yellowfin レポート:このモジュールは、クエリーエンジンからデータを要求し、必要に応じてそのデータを拡張し、要求されたビジュアライゼーションを生成します。クエリー定義には、各レポートまたはビジュアライゼーションの作成に必要なデータの詳細が含まれています。クエリーエンジンからデータが返されると、そのデータに対して追加の処理を実行する様々なサブエンジンがあります。
- 後処理エンジン:このエンジンは、クエリーからロウデータを取得し、表示の準備をします。これには、異なるデータソースからのデータの結合、データのクロス集計の実行、データ型の変換、データの書式設定、複雑な後処理の実行によるデータの拡張が含まれます。後処理には、高度な統計計算の実行(合計比率、標準偏差、予測など)や、データを拡張するためのサードパーティ製アプリケーションの呼び出し(ETLエンジンと同じフレームワークを使用した予測データサイエンスモデルの起動など)が含まれます。後処理関数は拡張可能であり、クライアントは、データが表示される前に特定の処理を実行するための独自の関数を書き込み、含めることができます。
- ビジュアライゼーションエンジン:このエンジンはレポート、グラフ、ダッシュボード、プレゼンテーション、ストーリーなどの表示コンテンツを生成します。このフレームワークも拡張可能であり、例えば、JavaScript グラフや、他のカスタムUIコンポーネントを含めることができます。
- ロウデータプロバイダー:レポートから返されたデータセットには、APIの呼び出しを介してアクセスできます。顧客は、Yellowfin ビジュアライゼーション、または顧客が開発したカスタムUI要素でデータを表示する前に、基礎となるデータセットに対してカスタム処理を実行できます。
- データキャッシュ:Yellowfinは、エンドユーザーエクスペリエンスを高速化するために、データをキャッシュするように設定できます。実際のレポートデータ、フィルター値、お気に入りなど、様々なデータをキャッシュできます。データ更新は、Yellowfin スケジューラーを使用して、スケジュール設定することができます。
コンテンツレイヤー:コンテンツは、最も一般的なブラウザや、Yellowfin モバイルアプリ(IOS、またはAndroid)から、Yellowfin アプリケーションを介して使用することができ、個々のコンポーネントは、APIの呼び出しを介してアプリケーションに組み込むことができます。ユーザーは通常、ダッシュボードやプレゼンテーション、ストーリーを介してYellowfin ビジュアライゼーションと対話するか、サードパーティ製アプリケーションに直接組み込まれたビジュアライゼーションと対話をします。コンテンツレイヤーは、顧客のニーズに合わせて再設計し、カスタマイズすることができます。コンテンツレイヤーでは、次のようなその他機能も使用できます。
- サードパーティ製コンテンツ:ストーリー製品から、サードパーティ製BIアプリケーションからのビジュアライゼーションをYellowfinに組み込むことができます。Tableau、Qlik、PowerBIからのコンテンツを結合し、Yellowfinのコンテンツと合わせて閲覧できます。
- タイムラインフィード:タイムラインフィードは、Yellowfin アプリケーション、モバイルアプリ、またはREST APIを介して、パーソナライズされたアラートや関連コンテンツを提供します。
スケジューリングエンジン:ETLジョブ、レポート配信、シグナルジョブ、およびその他のシステムタスクをスケジュールするための柔軟なスケジューリングエンジンが含まれています。一部のスケジュールされたタスクは、例えば、事前に定義された閾値を超えた場合にトリガーされます。
シグナルエンジン:シグナルエンジンは、重要なデータイベントを識別するためにデータを自動的に解析し、ブラウザクライアント、またはモバイルクライアントのいずれかでタイムラインフィードを介して配信される、パーソナライズされたアラートを生成します。シグナルジョブは、メタデータレイヤーで構成および活用され、スケジューリングエンジンを使用して任意の頻度で実行するようにスケジュール設定できます。シグナルエンジンは複雑で、時系列生成エンジンや、複数のイベント検出アルゴリズム、ランク付けやパーソナライゼーションエンジン、通知エンジンを含んでいます。
自動インサイトエンジン:これは、自動的にその場でデータインサイトを生成するために呼び出される一連のアルゴリズムです。これらのインサイトは、レポートビルダープロセスを通したグラフビジュアライゼーションや、ユーザーとの直接的なインタラクションを通じてアクセス可能であり、シグナルの背後にあるさらに詳細な説明を提供します。
-
テクニカルアーキテクチャー
Yellowfin プラットフォームアーキテクチャーの主要なコンポーネントは何ですか?
Yellowfinは、(Apache Tomcat上で動作する)Java アプリケーションサーバと、リポジトリデータベースから構成されています。リポジトリデータベースは、以下のサポートされているデータベースシステムのいずれかに配置することができます。PostgreSQL、Microsoft SQL Server、MySQL、Oracle、DB2、Ingres
アプリケーションは、同じリポジトリデータベースに対して複数のYellowfin アプリケーションサーバをクラスタリングすることで、より優れたキャパシティとフェイルオーバーのために拡張することができます。
アプリケーションサーバ
Yellowfinを実行するために、どのようなアプリケーションサーバを使用できますか?
Yellowfinは、インストール中にTomcatのインスタンスをインストールします。サードパーティ製Javaアプリケーションサーバの使用を希望するクライアントは、既存のインフラへの導入のために、WARファイルとしてYellowfinを使用することができます。
Tomcatには、Yellowfinを既存のウェブサイトやポータル上で公開できるようにするために、外部のウェブサーバとの統合を可能にするいくつかのコネクターがあります。これには、Apache、IIS、Nginxが含まれます。
Yellowfinに同梱されている外部の独自コンポーネントやライブラリはありますか?
Yellowfinに同梱されている独自のライブラリはありません。
Yellowfinにはどのようなオープンソースライブラリが同梱されていますか?
Yellowfinには許可を得たオープンソースのライブラリが数多く同梱されています。これらすべての一覧は、Yellowfinのインストールディレクトリに記載されています。
レポートデータがYellowfinに保存されることはありますか?
Yellowfinは、レポートやダッシュボードが閲覧されている間に、一時的にデータをメモリに保存します。デフォルトでは無効になっているその他のオプションでは、レポートやフィルター値をリポジトリデータベースにキャッシュできます。これはレポートのスナップショットを作成し、ユーザーがドロップダウンリストからフィルター値を選択できるようにするために使用します。レポートデータキャッシュは、メモリにデータを格納することもできます。これにより、設定可能な期間内に再利用するために、レポートクエリーのデータセットを保存します。
リポジトリデータベース
構成データはどこに保存されますか?
ユーザー、グループ、コンテンツ定義を含むすべての構成データやメタデータは、リレーショナルスキーマのリポジトリデータベースに格納されます。このデータベースは、インストール時に作成され、サポートされている次のいずれかのデータベースシステムに配置できます。PostgreSQL、Microsoft SQL Server、MySQL、Oracle、DB2、Ingres
構成データをバックアップするにはどのようにすればよいですか?
リポジトリデータベースをバックアップすることで、Yellowfinの構成を完全にバックアップできます。バックアップは定期的なスナップショットや、システム間での環境移動またはクローン作成に使用できます。ログシッピングやクラスタリングなどのデータベース機能を使用すると、構成データをリアルタイムでバックアップし、フェイルオーバーとディザスターリカバリーを実現できます。
-
オープン性と拡張性
どこにでも導入可能
どのようなOSに導入できますか?
Yellowfinは、Windows、Linux、またはMac OSXベースのデスクトップまたはノートPCにインストールして評価やトレーニングを行い、Windows、Linux、またはMac OSXベースのサーバにインストールして評価、トレーニング、および運用を行うことができます。
どのようなクラウド環境に導入できますか?
YellowfinはAWS、Azure、GCPなどの主要なクラウドプロバイダーと連携しています。
Yellowfin インスタンスをオンプレミスで実行することはできますか?
できます。オンプレミス、またはクラウドに導入可能です。
ベンダー依存なし
Yellowfin プラットフォームに依存するのを避けることはできますか?
ESCROW(エスクロー):Yellowfin側が債務超過に陥った場合、プラットフォームのソースコードへのアクセスを許可します。
Yellowfinの使用を中止していても、(ユーザーが所有している)コンテンツデザインやコード拡張へアクセスすることで、アプリケーションやダッシュボードの豊富なビジュアルコンテンツやコード拡張を使用して、別のプラットフォームやテクノロジーでの再設定が可能です。
データは任意のデータベースに保存できます。このデータベースは、ユーザーが所有し、いつでもアクセスすることができます。
独自のデータベースに依存することになりますか?
いいえ。Yellowfinには、独自のデータベースやインメモリデータベースはありません。すべてのデータは、一般的に使用される任意のデータベース管理システムに格納されます。
その結果、いつでもデータにアクセスして他のツールに使用したり、任意のDBMSにデータを移行したりできます。
独自のスクリプト言語を習得する必要はありますか?
いいえ。Yellowfinには、データを移行したり、可視化したりするための独自のスクリプト言語はありません。Yellowfinは、すべてのプロセスで共通の業界言語、またはドラッグ&ドロップ機能のみを使用します。例えば、Yellowfin メタデータレイヤーを作成するには、ドラッグ&ドロップGUI、またはSQLを使用します。また、ダッシュボードのコードモードには、HTML、JavaScript およびCSSを使用します。
どの環境でもYellowfinをホストすることができますか?
Yellowfinを使用すると、オンプレミス、データセンター、またはAWS、Azure、Google、Oracleなどの任意のクラウドプロバイダーに導入することができます。
既存のデータウェアハウス環境を使用できますか?
Yellowfinは数多くのDBMSに接続し、独自のフォーマットにデータを取り込みません。そのため、データが既に準備されていて、レポート作成に適した形式であれば、データを移行したり、データに対してさらなる作業を行う必要はありません。データウェアハウスに接続し、コンテンツの構築を開始するだけです。
公開されたAPI
YellowfinはどのようなAPIを公開していますか?
Yellowfinには、2つの主要なAPI機能があります。
JavaScript API:レポートやダッシュボードコンテンツを、サードパーティ製アプリケーションに組み込むために使用します。
WebサービスAPI:管理タスクの自動化、ユーザーやメタデータのセキュリティ権限などのコンテンツのプログラムによる操作や、コンテンツのアプリケーションへの統合(ウェブアプリケーションやモバイルアプリ)に使用される豊富な種類のサービスです。SOAPとREST webサービスの両方がサポートされています。
Yellowfinのプロセスを自動化できますか?
Web サービスレイヤーを使用して、様々な管理プロセスを自動化できます。
既存のスキーマに基づき、Yellowfinに自動的にデータモデルを作成できますか?
できます。メタデータモデルは、webサービスを使用して直接操作することも、コンテンツファイルを合意された標準の外部で構築し、インポートwebサービスを使用してYellowfinにインポートすることもできます。
拡張性
Yellowfinの機能を拡張するにはどのようにすればよいですか?
Yellowfinは、様々な方法で機能を拡張します。カスタムワークフローやユーザーエクスペリエンスを作成したり、プラグインコンポーネントを使用して拡張機能を追加したりできます。何ができるかについて、より詳細な情報は、Yellowfinの拡張の項目を参照してください。