
Yellowfinのクールな機能パート3: 高度なクエリー生成
本ブログシリーズでは、Yellowfin CTOであるBrad Scarffが、Yellowfin 組み込みアナリティクス製品の最もクールでユニークな機能について紹介します。
高度なクエリー生成は、人工知能、機械学習、自然言語などの高度な技術を使用して、複雑なデータ分析を効率化します。
これが現在組織またはソフトウェアアプリケーションに選択しているアナリティクスツールの重要な部分である理由を理解するには、今日の一般的なデータシナリオを検証することが重要です。
Yellowfinのクールな機能シリーズの第1回および第2回では、標準的なレポートの見栄えを良くする機能と、高度なブロードキャスト経由でレポートを配信するための強力で柔軟な機能に焦点を当てました。本ブログでは、レポートのいくつかの基本的な側面 (高度なクエリー生成) に戻り、データを詳細に掘り下げることのできるYellowfinの様々な機能について詳しく紹介します。
高度なクエリー生成概要
ビジネスインテリジェンス (BI) とアナリティクスアーキテクチャーの大部分には、その中核にデータストレージの仕組みと、そのデータストレージからデータを照会する方法があります。データストレージはBIツール自体にバンドルされていることもあり、便利である反面、組み込みデータベースはBIベンダーへのロックインを高め、可用性と柔軟性を制限します。
より一般的には、市販のDBMS (データベース管理システム) が使用されます。これには、Oracle、SQLServer、PostgreSQLのような汎用の多目的DBMSから、SnowflakeやExasolなどの高速分析スタイルクエリーのための特定の最適化を含む特別な目的の分析DBMSまで様々です。未だ旧式のキューブ型アーキテクチャーも使用されていますが、その人気は衰えつつあるため、今回これらは取り上げません。
ほとんどの場合、レポートDBMSクエリーはSQL文の形式になります。多くの技術ユーザーや一部のビジネスユーザーは、大学または社会人キャリアの中でSQLスキルを学びます。BIツールでは、ユーザーがSQLを記述する必要性がほとんどなくなり、代わりにクエリー生成メカニズムによってSQLを生成します。ユーザーは通常、ビジュアルベースのユーザーインターフェース (UI) を介して、レポートフィールドのドラッグ&ドロップ、フィルターや並べかえ順の指定など、クエリーから必要なものを定義するために様々な方法を使用します。
最近では、自然言語で質問を入力することが、ユーザーがクエリーを生成または開始するための一般的な方法になっています。例えば、Yellowfinは、自然言語を活用したガイド付きNLQにより、データベースへの照会プロセスを、従来のデータ探索手法よりもはるかにアクセスしやすく、視覚的なものにしています。
多くのものと同様に、SQLクエリーは単純なものから複雑なものまであります。ほとんどすべてのBIツールは確かに基本的なことは網羅できますが、複雑なクエリーやさらに高度なクエリーの生成になると、多くのツールが手薄になります。Yellowfinのクエリー生成エンジンは、利用可能な中で最も広範で強力なものの1つであり、あらゆるタイプのSQLクエリーを生成することができ、実際、SQLだけでは作成できないクエリーを生成することもできます。次のセクションでは、Yellowfinにおけるこれらのいくつかの機能について紹介します。
基本的なクエリーの構築
データの選択 (SELECT)
まず、Yellowfinは従来のカラムベースのレポーティングをサポートしており、フィールドは利用可能なフィールド一覧から「ドラッグ&ドロップ」されます。利用可能なフィールドは、ビューとして知られる、Yellowfin メタデータレイヤーで定義されます。このレイヤーは、結合ルールなどの技術的な複雑さを隠し、ビジネスで理解できる名前、書式、集約ルール、計算式、その他の設定を適用する場所でもあります。ビューレベルで定義された構成は、そのビューから作成されたレポートで自動的に共有されます。これにより、レポートの一貫性と再利用による効率性が保証されます。
データフィールドは、カラム (列) またはロウ (行) として定義できます。これにより、次のようなクロス集計レポートを作成することができます。カラムおよびロウ項目の両方に複数のディメンション (次元) カラムを追加でき、複数のメトリック (数値) を追加することもできます。
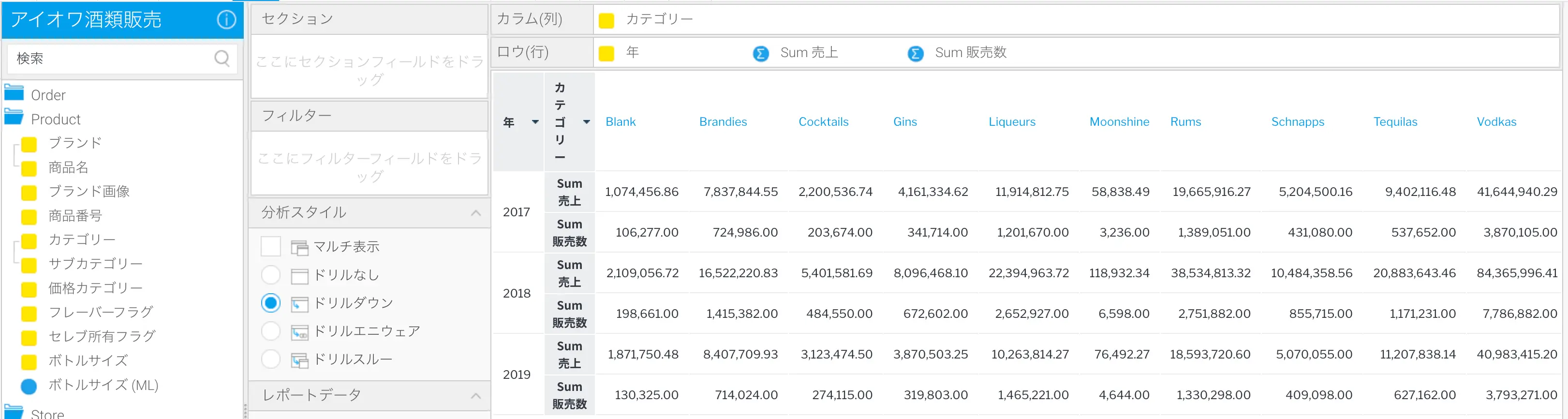
ユーザーが望めば、Yellowfinが生成したSQLをいつでも確認することができます。
計算式の作成
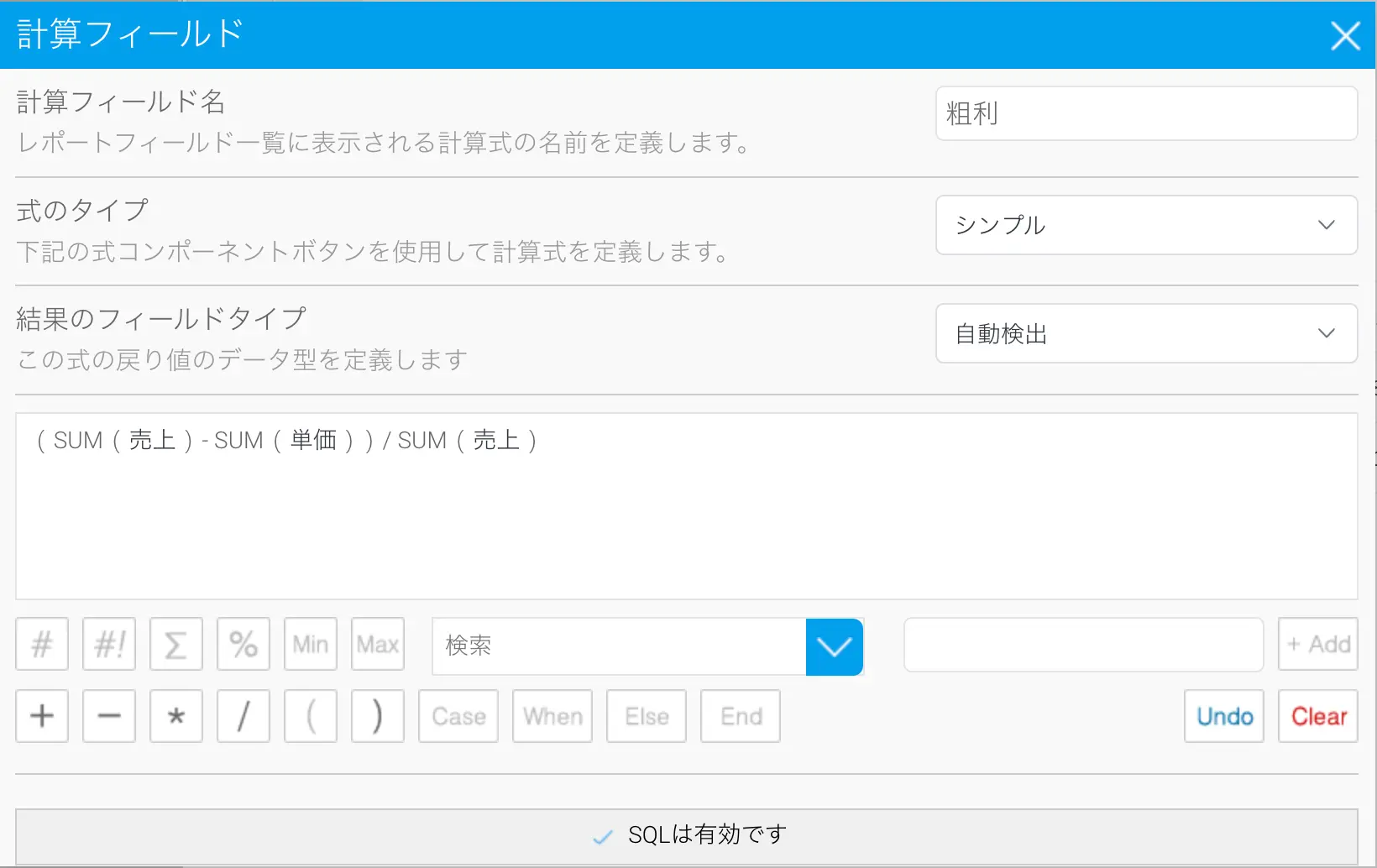
Yellowfin レポートビルダーは、高度な計算フィールドビルダーを備えています。これにより、追加のデータカラムを定義することができ、その実行は基礎となるDBMSに渡されます。ユーザーは、算術演算子、CASE文、定義済み関数を使用した複雑な計算式を構築することができ、フリーハンドSQLを使用して計算式を定義することも可能です。
以下の例では、マージンを計算するために集約値を使用した粗利計算フィールドを定義しています。これは、クエリーが平均値を集計して誤った結果を返すため、データベースに保存することができません。
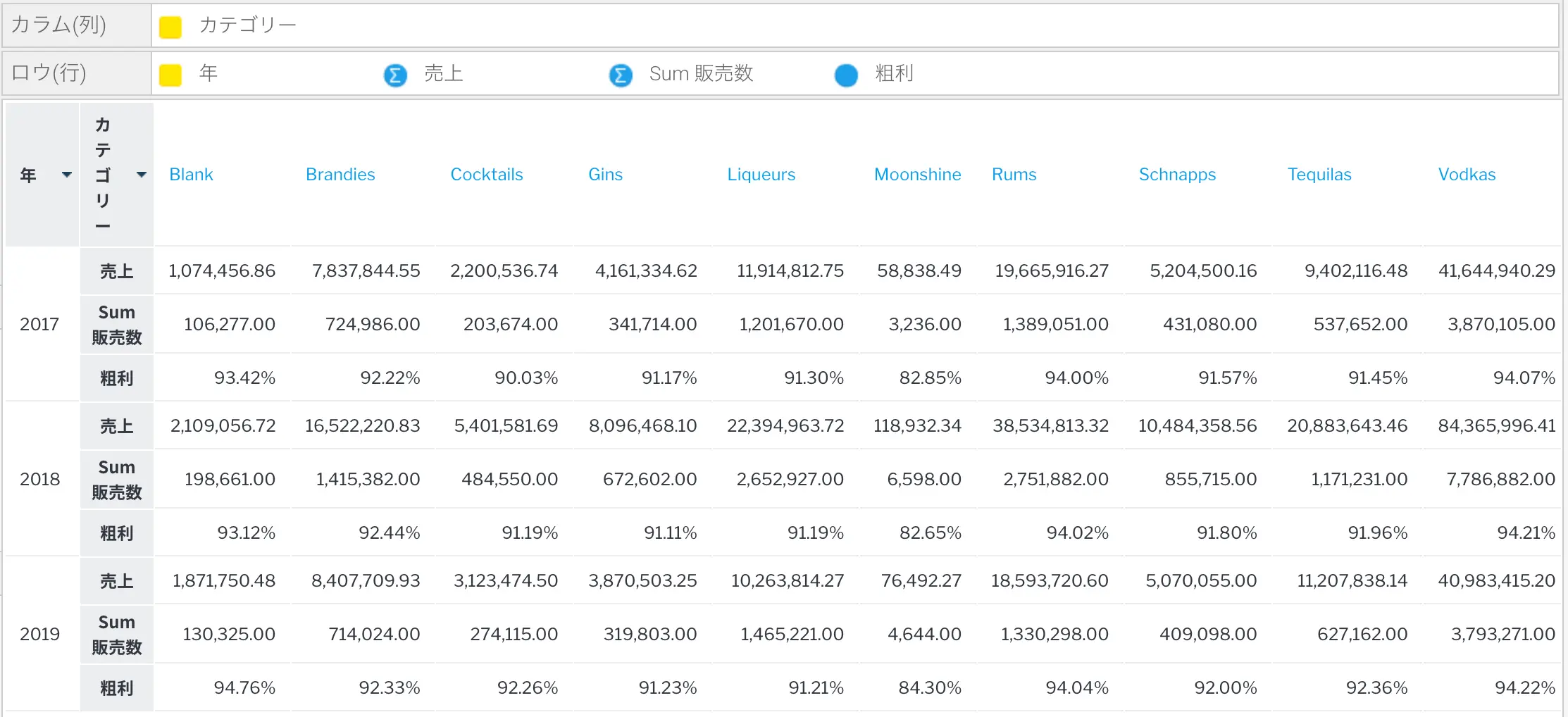
クールな機能ブログ第1回で、データの書式設定や、カラムやロウの見出し、セクションの区切り、値を強調表示する条件付き書式など、数多くの書式設定オプションが用意されていたことを思い出してください。
集約の作成 (GROUP BY)
Yellowfinのクエリージェネレーターは自動的にGROUP BYカラムを作成し、集約が定義されていないフィールドをグループ化します (SUM、COUNT、AVGなど)。
データのフィルタリング (WHERE)
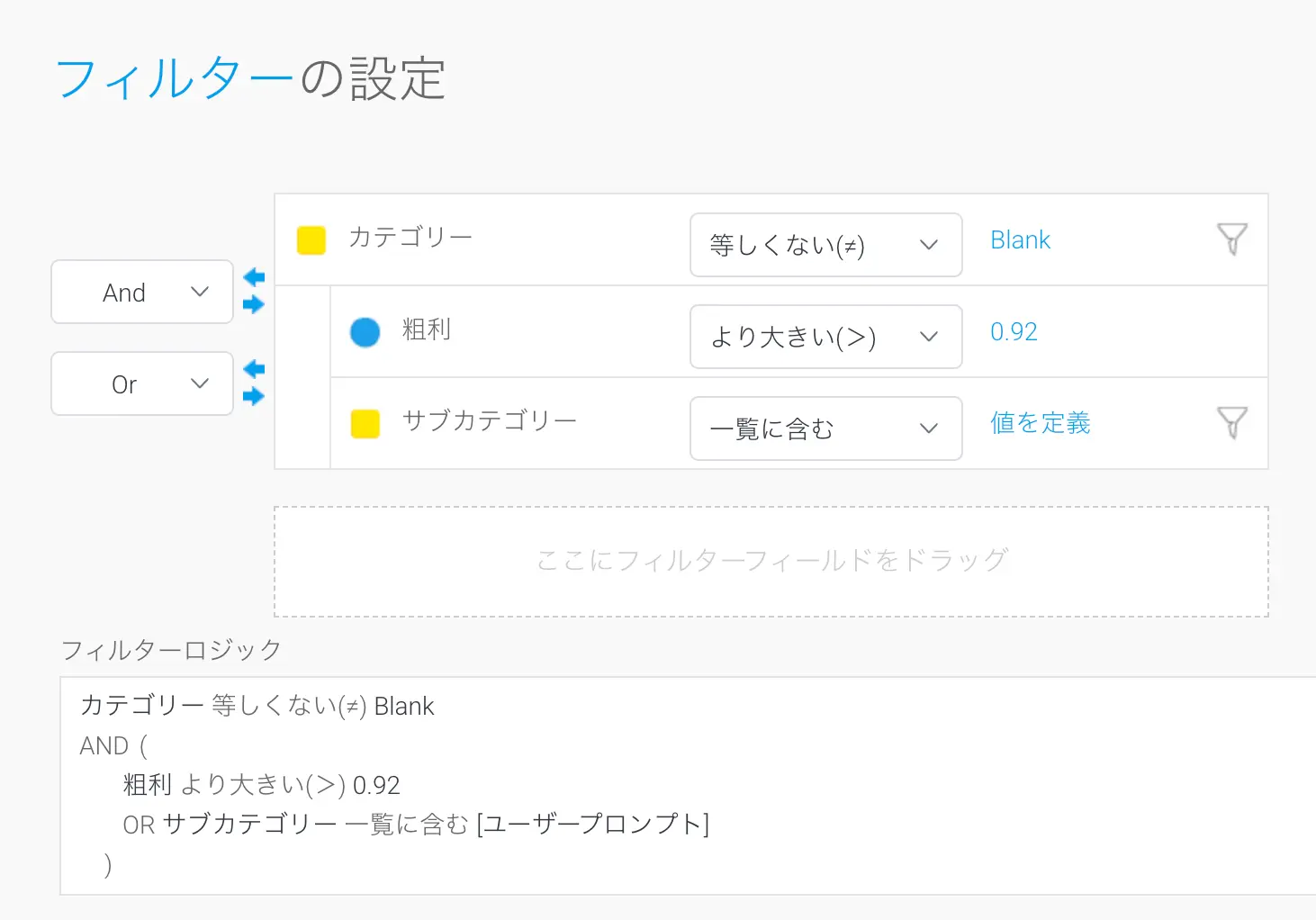
レポートビルダーには高度なフィルター機能があり、DBMSでサポートされているあらゆるタイプのWHERE句を生成することができます。フィルターは、フィルター項目にフィールドをドラッグして定義します。演算子を定義する必要があり、これは数値フィールドや日付に適用できる等しい (=)、等しくない (≠)、より大きい (>)、より小さい (<)、の間 (〜)、IS NULL、IS NOT NULLなどの論理演算子や、一覧に含む、一覧に含まないなどのカテゴリー値演算子から選択します。
高度なフィルターロジックにより、これらの条件を論理構造にグループ化し、AND/ORや括弧を組み込むことができます。フィルター値はレポートレベルで事前に設定することも (例えば、フィルターを設定することで、常にこのレポートの日付=昨日となるようにします)、ユーザープロンプトとして設定することもできます。フィルターをユーザープロンプトとして定義した場合、フィルターはレポートに表示され、エンドユーザーはレポート実行時に値を指定できます。フィルターはオプションまたは必須として定義することができ、事前にデフォルト値を設定することもできます。値の一覧を含むフィルターの場合、値はクエリーからなど、様々な方法で事前に設定できます。
クエリーが長時間実行される場合は、ユーザーがこれらのフィルターに動的にアクセスしてもパフォーマンスの問題が発生しないように、クエリーをバッチで実行するように構成できます。最後に、あるフィルター内の値が選択された他のフィルターに基づいて制限されるように、フィルター同士をリンクさせることができます。
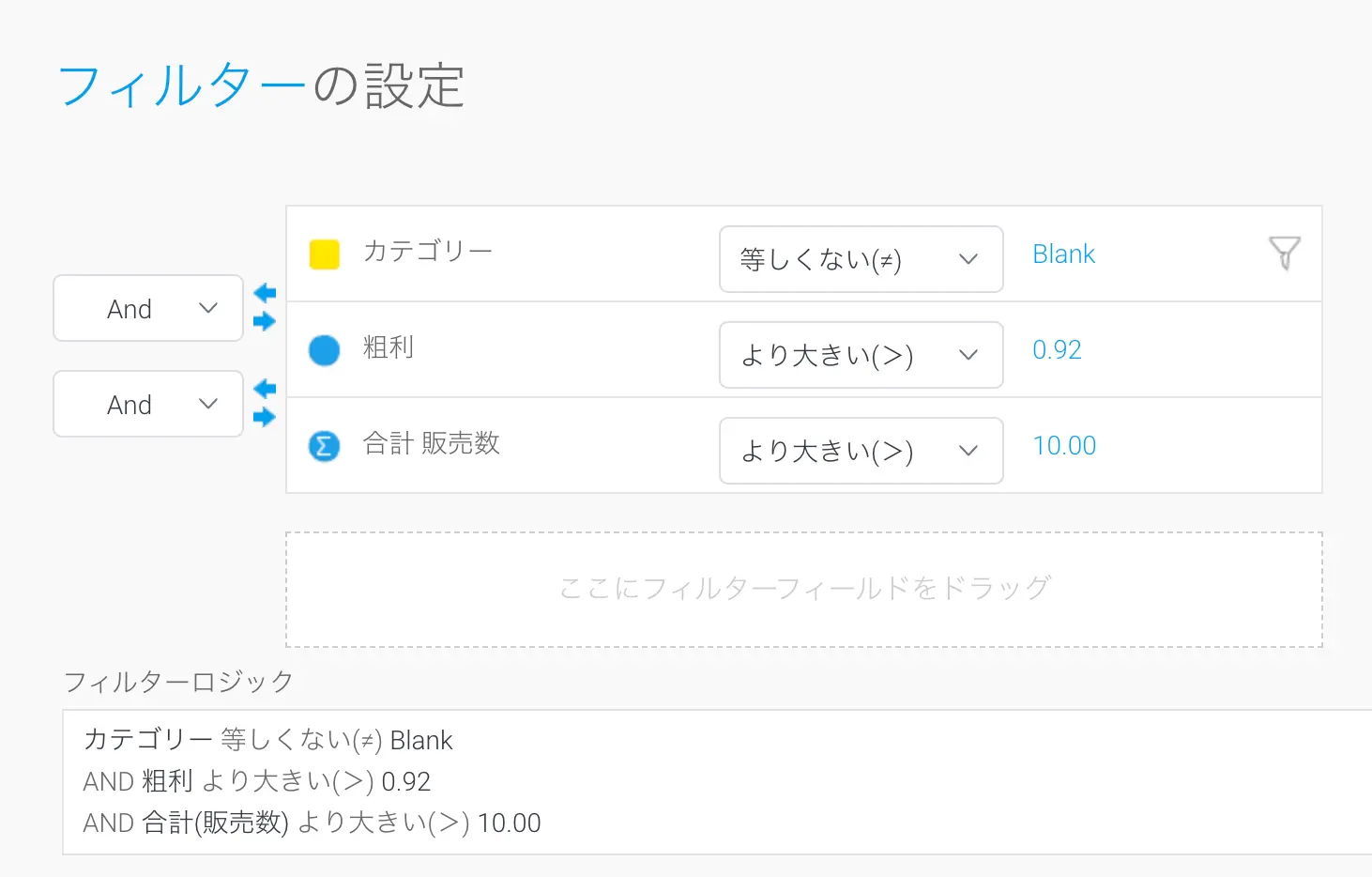
集約のフィルタリング (HAVING)
場合によっては、集約の結果に基づいてデータをフィルタリングしたいこともあるでしょう。デフォルトでは、SQLのWHERE句は集約の結果セットではなく、データの最小粒度で適用されます。集約レベルでのフィルタリングは、HAVING区を適用することでSQLで実現されます。メトリックでフィルタリングをする場合、ユーザーには集約を適用または削除するオプションがあります。集約が適用されない場合、個々のメトリックカラムはWHERE句でフィルタリングされます。集約が適用される場合、フィルター条件はHAVING句に移動し、条件は集約レベルで適用されます。
例えば、商品の注文を含むデータがある場合、販売数>10 というフィルターを適用すると、個々の注文レベルで適用され、条件はWHERE句に追加されます。同じフィルターを適用しますが、販売数にSUM集約を追加すると、この条件はHAVING句に移動し、データが集約されグループ化された後にフィルタリングされます。したがって、商品名でグループ化した場合、次に示すように、販売数の合計が10を超えるすべての商品を取得することになります。
データの並べかえ (ORDER BY)
並べかえ順は複数のカラムに適用することができ、生の値と書式設定後の値を並べかえるオプションがあります。Yellowfinの参照コードを使用することで、特定のフィールドに対してカスタマイズされた並べかえ順を定義することができます。さらに柔軟性を高めるために、Yellowfinは結果セットに高度な並べかえ順を適用し、SQLだけでは達成できない並べかえを実現することができます。
高度なクエリー構築
クエリーとサブクエリーの結合
レポートビルダーには、様々なサブクエリーを作成できるユニークな機能があります。
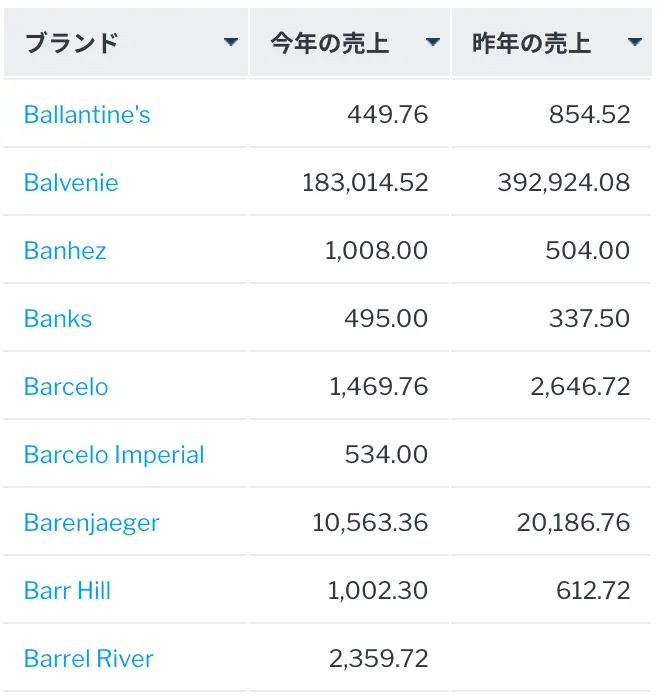
例えば、基本的な追加スタイルのサブクエリーを使用して、あるブランドの2年間の売上を比較することができます。
または、より複雑な例として、昨年は売り上げがなかったが、今年はは売上があったブランドについてレポートすることもできます。これは、マイナスサブクエリーを使用することで実現できます。

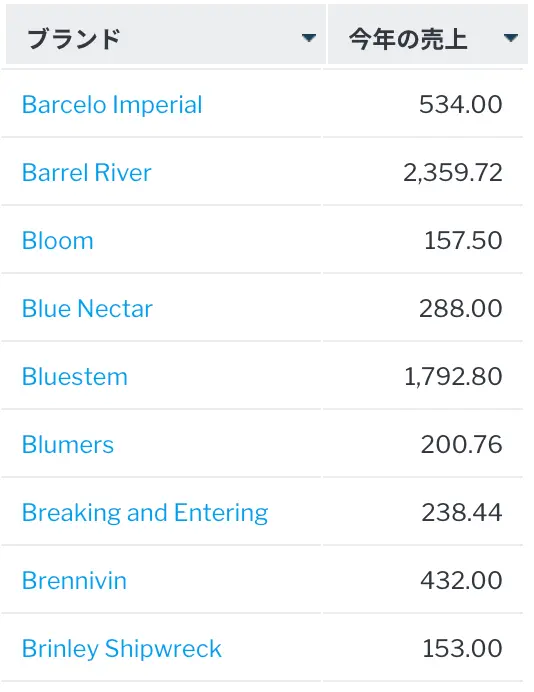
昨年に日付がないブランドだけが表示されています。
また、交差サブクエリーを使用して、両年に売上のあるブランドを表示するレポートを作成したり、2つのクエリー結果を相互に追加する従来の結合クエリーを作成することもできます。
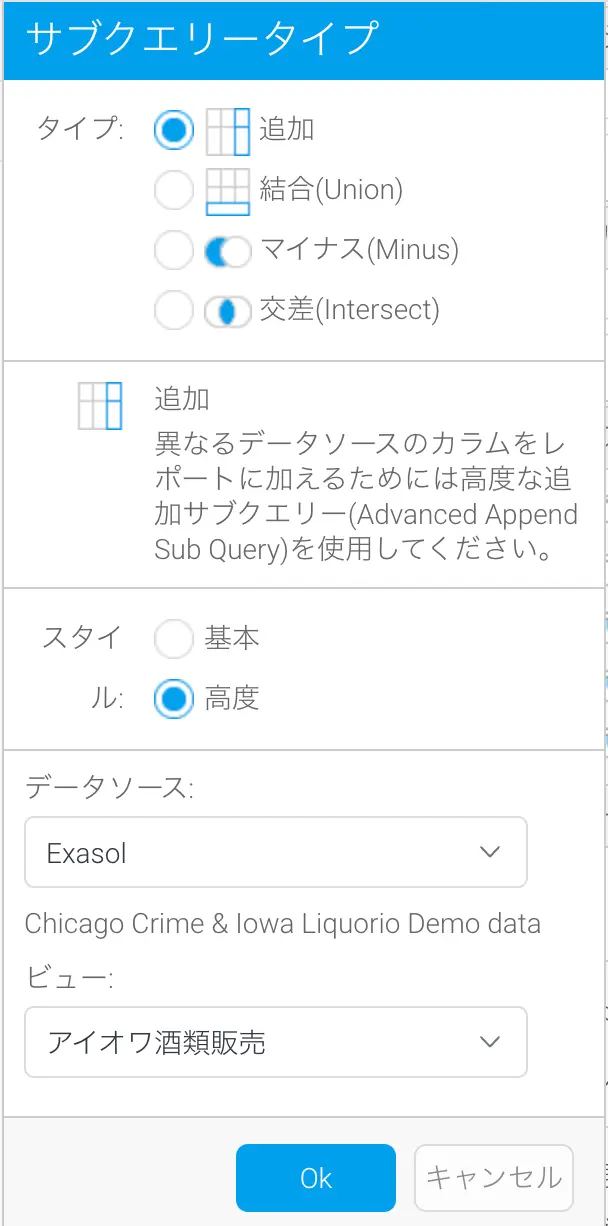
高度なサブクエリーを使用したデータセット間のデータ結合
各サブクエリータイプは、同じビューからデータを取得する基本サブクエリーか、高度なサブクエリーのいずれかになります。高度なサブクエリーでは、親クエリーとは異なるビューからデータを取得することができます。このビューは、全く別のデータソースからデータを取得することができます。つまり、セールスデータと人事データを、異なるデータベースの営業担当者に関するデータと組み合わせることができます。
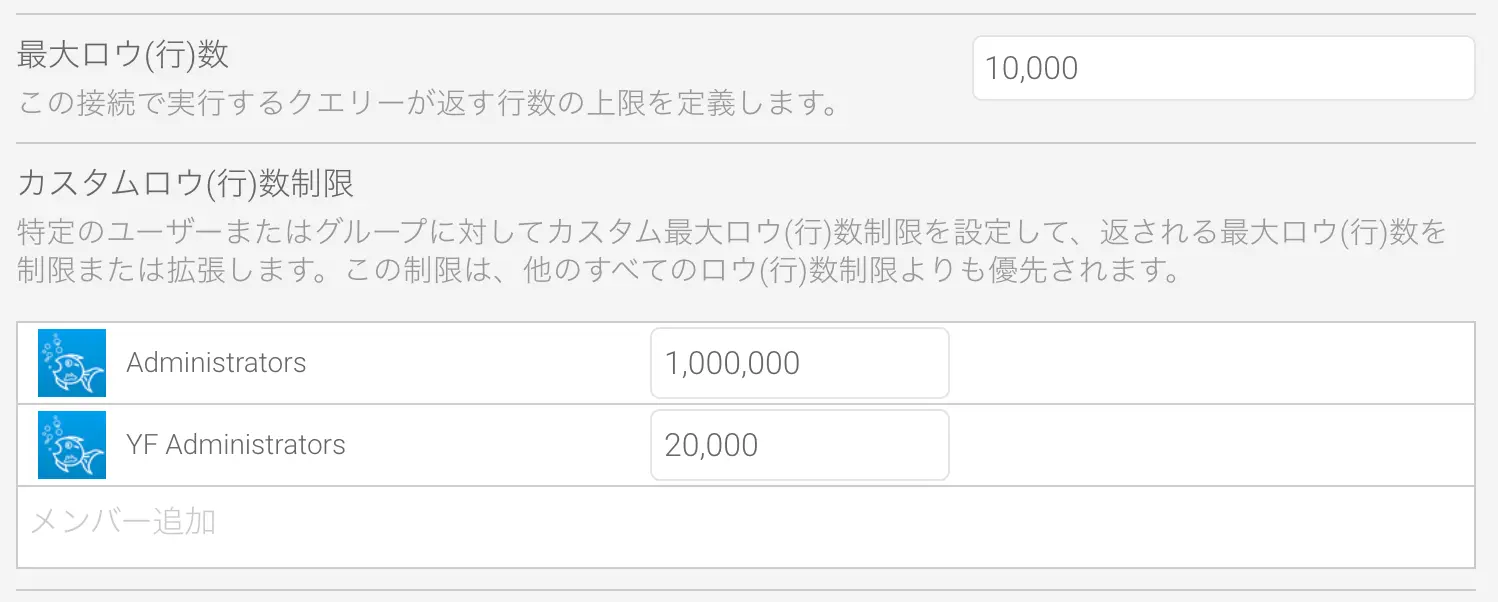
システムを過負荷から守る
データベースが非常に大きい場合、ユーザーが非常に時間のかかるクエリーを作成する可能性があり、SaaS DBMSの場合にはコストが高くなることになります。Yellowfinは、大規模なクエリーの実行からシステムを保護するために複数のセーフガードを備えています。ロウ (行) 数制限はデータソースレベルで構成でき、個々に変更することができます。そのため、経験豊富なユーザーは行数制限を大きくし、経験の浅いユーザーには厳しく制限することができます。
レポート作成プロセス中に、クエリーの行数制限を動的に構成したり、クエリーの自動更新を無効にすることもできます。この場合、サンプルデータが使用されるため、レポート作成が非常に迅速になり、クエリーは要求時にのみ実行されます。
ガイド付きNLQを活用する
Yellowfinのガイド付きNLQ (自然言語クエリー) 機能を使用することで、アナリティクスユーザーは質問を入力することでレポートを作成できます。他のNLQ実装とは異なり、ガイド付きNLQは様々な可能性のあるオプションを通してユーザーを段階的に誘導し、質問プロセスをよりシンプルにします。
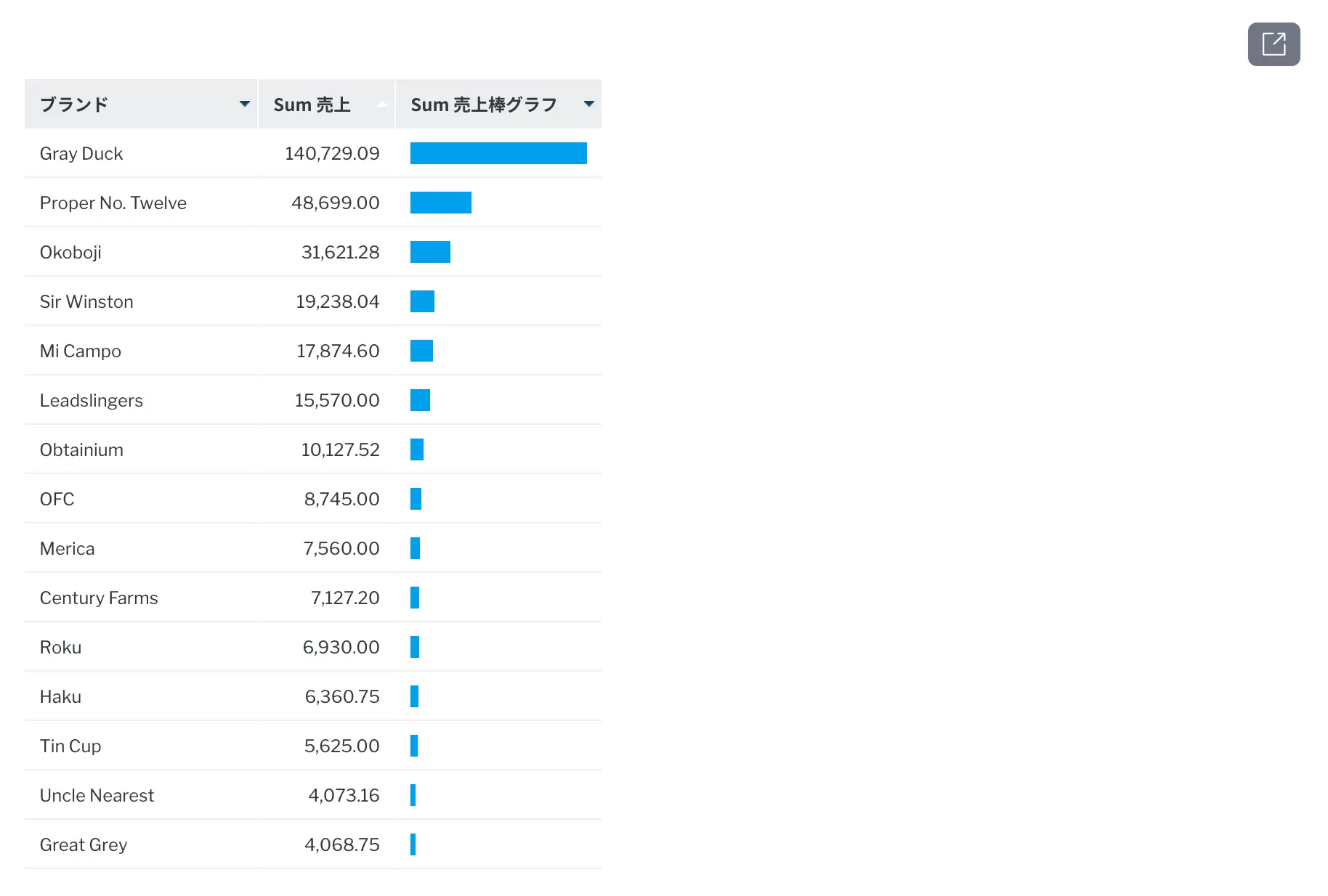
NLQは経験の浅いユーザーを対象としていますが、経験豊富なレポート作成者が複雑なレポートの作成を開始する迅速な方法として使用することもできます。例えば、昨年ではなく今年の売上があるブランドを見つけるために高度なサブクエリーを手作業で作成するのではなく、次のようにガイド付きNLQに入力することができます。

すると、Yellowfinは次のようなレポートを作成します。
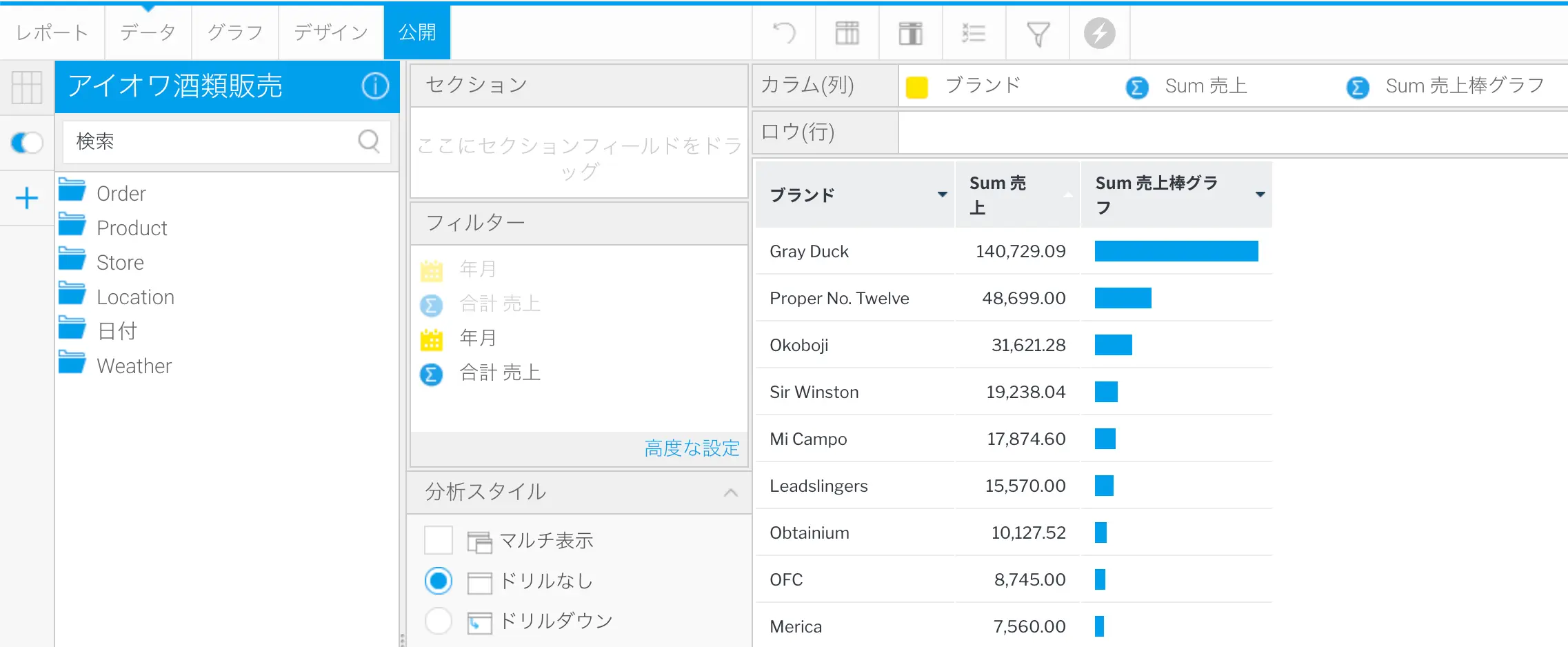
裏側では、完全なレポートが作成されています。ユーザーは画面右上の矢印をクリックすることで、このレポートを開くことができます。これにより、フィールドの書式設定、サブクエリー、グラフなどを含む、完全に定義されたレポートがレポートビルダーで起動されます。このレポートは、ドラッグ&ドロップを使用して作成された通常のレポートと同様に使用することができます。
Yellowfinのその他のクールな機能
今回のブログはいかがでしたでしょうか。今後のブログでは、レポート内で高度な計算を作成する機能など、より複雑なレポートトピックを紹介します。これらは最終的な結果セットに対して実行され、最頻値や標準偏差のような計算や、その他の多くの複雑な数学的、統計的、書式設定的関数を使用できます。
また、Yellowfinを最大限に活用していただくために、グラフ関数 (予測など) やSet分析など、基本的なものから高度な概念までを網羅するグラフの探索も実施予定です。
Yellowfin ガイド付きNLQをお試しください
Yellowfin ガイド付きNLQの仕組みにご興味をお持ちであれば、サンプルデータセットを使用したデモをお試しください。セールスチームまでお問い合わせお待ちしております。
「デモをリクエスト」
製品の紹介資料はこちら↓
