
WhereScapeについて
はじめに
Yellowfinが属するIderaグループは、傘下に数多くのソフトウェベンダーを抱えています。特に、データベースに関わる技術に強く、Yellowfinと組み合わせることで、より利便性が高まるソフトウェアも多々存在します。
その中から、WhereScape社が開発販売するWhereScapeを紹介します。Yellowfinが参照するDWHを効率的に構築できるソフトウェアで、大量のデータを処理することに優れ、DWH以外にも様々な目的に合わせたデータ構造を柔軟に構築することができます。WhereScapeが提供するソリューションが求められる技術的な潮流と合わせて、製品の特長を説明します。
◎製品資料をCheck!Yellowfinについて理解を深めよう↓

技術的潮流
ELT
DWHにデータを集約する際、分析に適したデータ構造としてスタースキーマに近づけることが望まれます。そのためにはデータを変換してDWHに取り込む必要があるのですが、最近ではデータ変換ツールとして、ETLに代わりELTの技術が普及し始めています。
ETLはデータをExtract(抽出)、Transformation(変換)、Load(書き出し)することを意味します。業務システムなどのデータソースからデータを抽出し、ETLでデータを加工してから、DWHに書き出します。DWHにデータを格納する前に、必要なデータの加工を済ませてしまうのが特徴です。
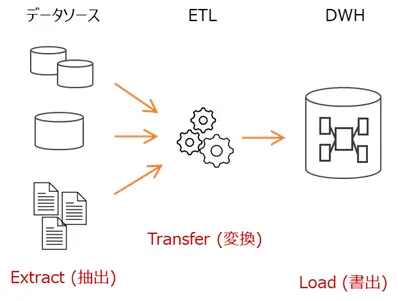
一方のELTは、データをExtract (抽出)、Load(書き出し)、Transformation(変換)します。データソースから抽出するデータを、まずはDWHに書き出してしまい、その後 DWH上でデータを変換して、分析に適したスキーマに作り替えます。昨今ではクラウド上にDWHを構築する場面が多くみられます。クラウド上のスペックの高いデータベース機能を利用したデータ変換処理が可能となるため、大量のデータを変換する場合などに適しており、ETLに代わる選択しとして普及が進んでいます。
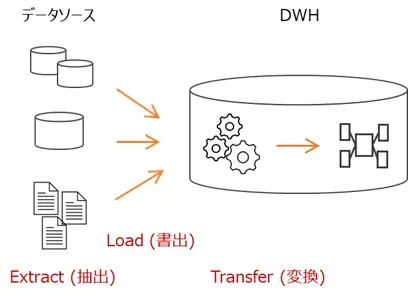
ETLとELTの説明に関する詳細は、下記サイト(外部)をご覧ください。
Data Vault 2.0
Data Vaultは、アメリカ人のデータアーキテクトであるDaniel Linstedt氏が、DWHやBI向けに開発したデータモデリングの手法です。同氏は、1990年代にモデルを開発し、第1版を2000年代初旬に出版。2012年にData Vault 2.0が提唱され、第2版を出版しました。1.0ではデータモデルの概念中心だったものが、2.0では、データモデリングに加え、プロセスのデザイン、ETL/ELT向けの性能向上、アジャイル開発なども考慮されています(出所 Wikipedia)。アーキテクチャーに関しては、先述のELTとの親和性が高いことも特徴の1つです。
Data Vault 2.0の詳細に関しては、以前のブログをご覧ください。
WhereScape
ELTやData Vault 2.0を取り扱うためには、仕組みの導入が必要です。WhereScapeを活用すれば、ELT基盤でDWHを構築し、Data Vault 2.0の設計・運用を行うことができます。
機能概要
WhereScapeの主な役割はDWHの構築です。そのために、WhereScapeは、3D、RED、Data Vault Express (DVE) の3機能で構成されます。それぞれの役割は大まかに以下の感じです。
3D:データソース探索(リバースエンジニアリング)、データプロファイリング、データモデリング、メタデータ生成
RED:実行プロシージャの生成、スケジュール実行
DVE:Data Vaultデータモデリング
WhereScape自体、実データは管理しません。メタデータだけを管理し、実際の処理は全て外部のデータベースに委任します。
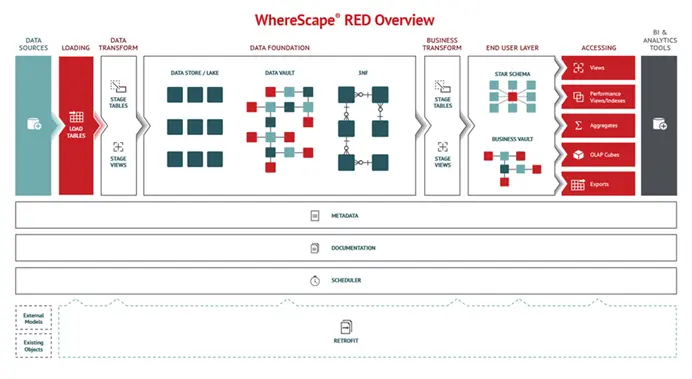
処理概要を下記イメージで説明します。左から順に、DATA SOURCES(データソース)から データをLOADING(ロード)し、DATA TRANSFORM(データトランスフォーム)で構造変換したものを、DATA FOUNDATION(データファウンデーション)に格納します。この時点で、データは様々な目的に継続利用されるものなので、中間ファイルとしてDATA STORE(データストア)、DATA VAULT(データボルト)、3NF(第3正規形モデル)などの構造で管理されます。さらに、BUSINESS TRANSFORM(ビジネストランスフォーム)でデータ構造が変換され、END USER LAYER(エンドユーザー層)でSTAR SCHEMA(スタースキーマ)やBUSINESS VAULT(ビジネスボルト)などの目的に応じたデータ構造で管理されます。BI(ビジネスインテリジェンス)やANALYTICS TOOLS(分析ツール)は、END USER LAYERのデータにアクセスし、データを可視化・分析します・
先述の通り、WhereScapeはメタデータだけを管理します。メタデータをもとに、データのロード、変換、生成などに関わるスクリプトやプロシージャを生成し、これらの実行を外部データベースに委譲します。
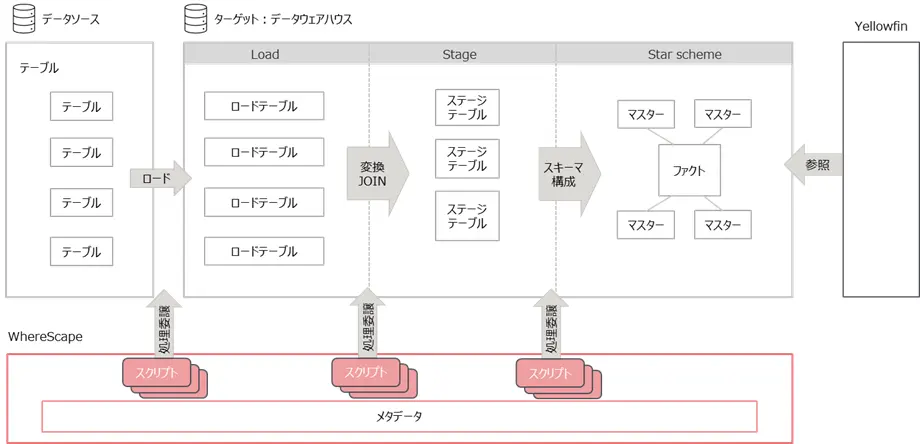
データソースから取り込んだデータを未加工のままDWHに取り込み、DWH上でスタースキーマに加工するまでの流れを簡素化したイメージが下記です。イメージ下部WhereScapeは外部データベースのメタデータを管理し、メタデータをもとに生成されたスクリプトで、外部データベースに対してデータのロードや変換などの実行を委譲します。データのロードや変換の実処理は、全て外部データベースのリソースを使って実行するため、パフォーマンスも外部データベースのスペックに依存します。クラウド上のデータベースの処理性能を活用できることから、データ量の多い処理を行う場面で強みを発揮します。いわゆるELTの処理の流れです。
Data Vaultデータモデリング
Data Vaultのデータモデリングは非常に複雑です。そのため、視覚的に優れたツールを使ってデータ構造をデザインし、その後は処理を自動化できる環境が必須といえます。WhereScape Data Vault Expressを活用することで、Data Vaultに特化したデータモデリングと運用を効率的に行うことが可能です。
データソースにアクセスし、データ構造を確認します。リバースエンジニアリングとしての役割も兼ねます。
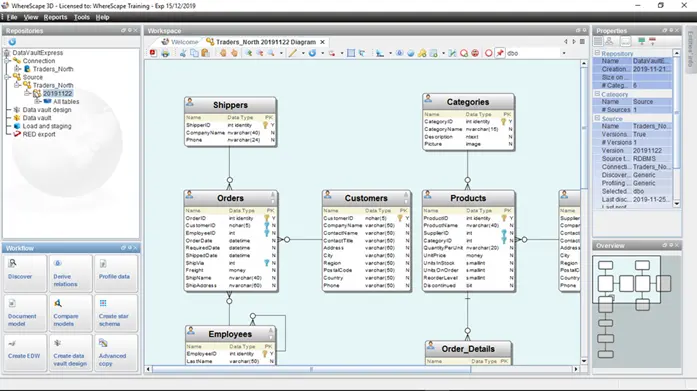
ステージングレイヤを介して、データを変換していきます。
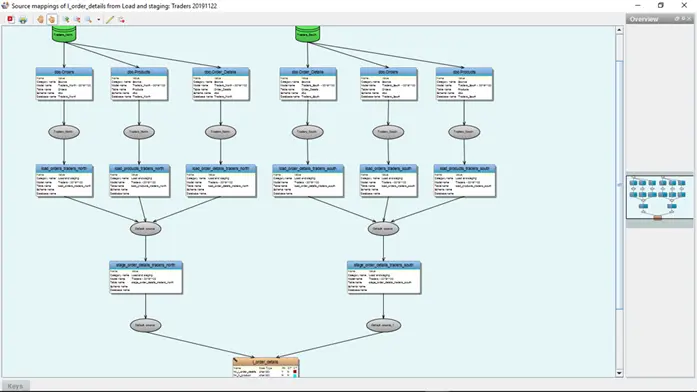
Data Vaultデータモデルを生成します。
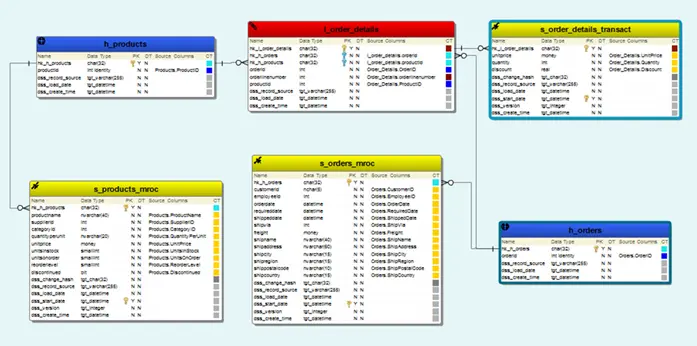
一度データモデルを生成してしまえば、定期的なバッチ処理として、日々の運用の中でデータが更新されていきます。
最後に
Ideraグループ傘下には、YellowfinやWhereScape以外にも、データベースに関わるソリューションを数多く抱えています。データの取り扱いに課題や要望をお持ちの方がいらっしゃれば、是非Yellowfinのセールス担当までお問い合わせください。最適なソリューションを紹介いたします。
チャートの作成方法や本記事に関する詳しい説明を聞きたい方はお気軽にお問い合わせください。
◎製品資料をCheck!Yellowfinについて理解を深めよう↓