
生成AIを用途に合わせてカスタマイズ – ファインチューニングとRAG
はじめに
OpenAI ChatGPT (Microsoft Copilot)、Google Gemini、Meta Llama など、各社が優れた生成AIのサービスを展開しています。生成AIを業務に活用する企業も急増してきており、代表的な用途としては、文書や資料の作成、翻訳、チャットボットなどが挙げられます。プログラムコードの作成にも生成AIの活用が有効で、ある程度の枠組みを生成AIに作成させ、あとは用途に合わせでコードを手動で修正するような開発の方法も現実的に可能です。
Yellowfinも生成AIと連携した機能を提供しており、AI NLQ(自然言語クエリー)の機能の中で、OpenAIのChatGPTと連携して自然言語を処理しています。

生成AIを業務に利用する際の課題
生成AIを活用するうえで、各社が直面する課題があります。それは、社内データやナレッジなど、一般公開されていない情報の活用です。
生成AIがLLM (大規模言語モデル) を構築するうえで、その深層学習を行うための膨大なデータには、インターネット上の公開データを活用することが一般的です。具体的には、生成AIはクローリングと呼ばれる技術を用いて、インターネット上の情報をかき集めて、深層学習しています。そのため、LLMが非公開情報を学習できない状況が起こり得ます。
例えば、Google GeminiにYellowfin Japan株式会社の社内規約を質問すると、以下のように回答しました。
「Yellowfin Japanの具体的な「社内規約」については、一般に公開されている情報は見つけることができませんでした。社内規約は企業の内部文書であり、通常は従業員にのみ開示されるため、外部から詳細を知ることは難しいです」。
生成 AI のクローラーは非公開情報にはアクセスできないため、当然の結果と言えます。

生成AIを自社向けに最適化
上記のような生成AIの課題を解決する技術として、ファインチューニングやRAG (検索拡張生成:Retrieval Augmented Generation) が存在します。いずれも、LLMが未学習の企業内データやナレッジを活用する点では共通していますが、その仕組みが異なります。
ファインチューニング
学習済みのモデルに対して、企業独自の非公開データなどを追加で学習させ、最適化を図ることをファインチューニングと呼んでいます。汎用性の高いデータを中心に学習しているLLMに対して、専門分野の未公開情報を追加学習させることで、自社の業務に適したモデルにチューニングすることができます。
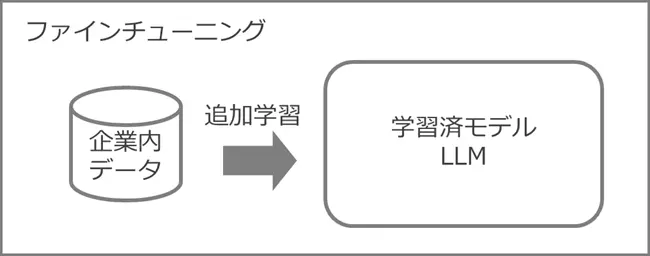
ファインチューニングの活用例と長所
1. 専門性の高い分野への活用
LLMの汎用的な情報だけでは法律文書、金融レポート、医療診断書など、専門性の高い分野の文章を作成するための情報が不足しています。そのため、専門分野に特化した情報を追加学習させて、各分野に適したモデルに調整することで、専門性の高い分野における自然言語の処理が可能となります。
自然言語以外にも、ファインチューニングによって、医療画像診断などの画像処理や、自動運転支援機能の提供など、用途に応じたモデルに調整することができます。
2. 独自表現への対応
企業や地域に適した表現や言葉遣いに対応することができます。
例えば、企業で独自に使われる言葉、ブランドイメージを意識した表現などを追加学習することで、各社に適した言葉や表現を使うチャットボットを構築することができます。また、地域固有の言葉遣いや地域性を意識した表現などへの対応にも有効です。
3. 自社の特性に最適化
言葉や表現以外にも、客層や市場の特性など、各社で固有の情報は多く存在します。こうした情報を追加で学習させ、自社の抱える顧客の傾向に適したモデルにチューニングし、レコメンデーションシステムなどに活用することも可能です。
4. ハルシネーション(幻覚)の抑制
生成AIを活用する上で、ハルシネーションが問題視されています。生成AIが、クローリングによってインターネットからかき集めた大量データを学習する中で、正しくない情報や偏重した情報も併せて学習してしまい、結果として誤情報や文脈に矛盾した情報を回答してしまう現象を、ハルシネーションと呼んでいます。特定の用途に特化した情報を追加学習することで、ハルシネーションを抑制する効果が期待できます。
5. プロンプトエンジニアリングの必要性を低く抑えられる
生成AIが目的に適した回答を返すために、質問の仕方を工夫して最適化を図ることを、プロンプトエンジニアリングと呼んでいます。ファインチューニングにより、プロンプトエンジニアリングにかかる手間を低く抑えることができます。
ファインチューニングの短所
1. 高品質なデータを大量に必要とする
最適なモデルの構築には高品質なデータを大量に必要とします。学習する追加データの質や量によっては、期待する結果が得られない場合があります。
2. 過学習
学習データに過剰適応してしまい、未知のデータに対する精度が劣化してしまうことを過学習と呼びます。追加学習したデータに過剰適応してしまった結果、過学習の状態に陥る可能性があります。
3. 開発の難しさ
ファインチューニングで追加学習するデータは、深層学習 (ディープラーニング) を介して学習します。ディープラーニングで精度高く学習するためには、バッチサイズやエポック数など、適切なパラメーターチューニングを行う必要があります。パラメーターチューニング次第では、望む精度に至らない場合もしばしばです。また、学習過程では、CPUなどのリソースを大量に消費します。
このような処理は追加学習を行う度に必要とされるため、追加学習に要する時間やコストが高止まりしがちです。
RAG (検索拡張生成)
生成 AI が未学習の情報を含む企業内データを検索した結果を伴って、生成 AI に質問を投げかけ、より精度の高い回答を得る仕組みがRAGです。RAGは日本語で検索拡張生成と表現されます。

RAGの活用例と長所
1. 生成AIの回答精度を向上
LLMが未学習の企業内データやナレッジを、生成AIを連携させることで、精度の高い回答や、特定用途に即した情報の生成が可能となります。具体的には、チャットボットやFAQシステムをRAGで構築することで、社内に蓄積されたナレッジ (FAQ、問い合わせ履歴、製品情報など) と生成AIを連携させ、高品質な回答を自動生成することができます。
また、自社の抱える顧客の特性に応じた市場調査やレコメンデーションシステムの構築、取り扱う製品を意識した最新技術情報の調査など、各社の状況に応じたコンテンツや仕組みの作成支援にも活用できます。
法律、金融、医療、研究など、専門性の高い分野においても、各社団体の特性に応じた文章作成支援につなげることができます。
2. ハルシネーションの抑制
企業内データから取得したデータに基づいて生成AIが回答を行うため、ハルシネーションの抑制につながります。
3. 透明性の高い回答
プロンプトの適切な設計などにより、出所が明確な情報を用いた回答を作成させることで、透明性の高い情報を生成することができます。
4. セキュリティ
生成AIに追加学習させる必要がないため、社内の機密データは社内に保有したまま運用することが可能です。
5. 更新の容易さ
企業内データは比較的容易に更新することができます。
RAGの短所
1. 専門性の高い情報や独自表現の取り扱い
ファインチューニングと比較して、専門性の高い情報を含む回答の生成に向かない部分があります。また、各社、各業界、各地域特有の表現や言葉遣いを求められる場面では、RAGではなく、ファインチューニングが適しています。
2. 企業内データの精度の重要性
精度の高い回答を得るためには、内部に持つ企業内データの精度や鮮度を常に高く保ち続ける必要があり、そのメンテナンスに関わる手間やコストが高止まりする可能性があります。
3. レスポンスの低下
企業内データの検索にかかる時間次第では、レスポンス遅延につながります。
Yellowfinのことを生成AIに聞いてみよう
では、Yellowfinについて生成AIに聞いてみましょう。素の状態のGoogle Geminiに問い合わせる場合と、RAGの仕組みを介してGeminiに問い合わせを行う場合とで、回答内容がどのように異なってくるのかを確認してみようと思います。
Geminiに直接質問
まずは、ブラウザからGeminiに直接アクセスして、下記の質問をしてみます。
「Yellowfinについて2行で説明してください」
すると、以下の回答が返ってきました。
「Yellowfinは、キハダマグロやコガネガレイといった魚の種類を指すこともありますが、IT分野ではAIによる自動分析機能を備えたビジネスインテリジェンス (BI) プラットフォームの名称としても使われます。このBIプラットフォームは、企業がデータを活用して意思決定を加速するための多様な分析ツールを提供しています。」
一般的に、Yellowfinといえばキハダマグロのことなので、上記のような回答が返ってくることはある程度予測がつきます。

RAGを使ってGeminiに質問
今度はRAGを使ってGeminiに質問します。企業内データを持つデータベースには、Yellowfin Japanが自社製品の紹介に用いる『Yellowfin紹介資料.pdf』に含む情報を登録しました。顧客への初回訪問時に使う目的の資料で、会社や製品の説明に加え、組み込みの分野での強みなどを説明するものです。
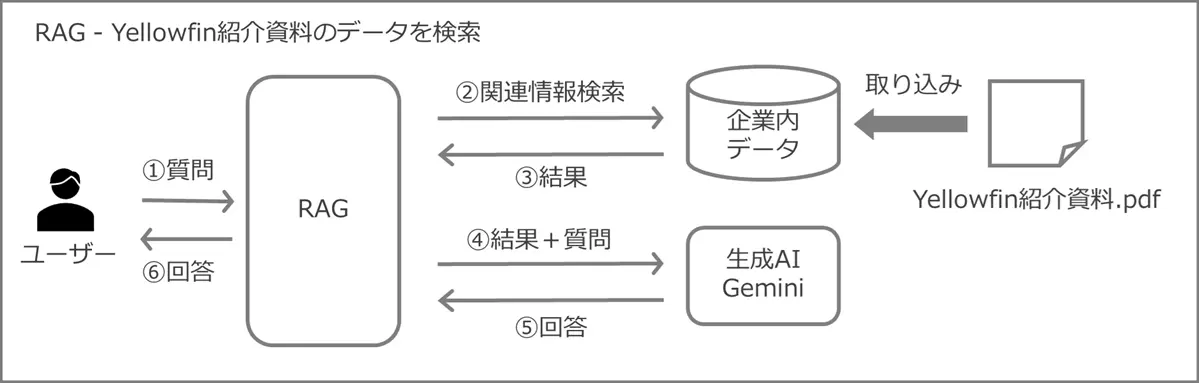
先ほどと同様の下記質問を投げかけます。
「Yellowfinについて2行で説明してください」
すると、以下のようにGeminiの回答が変わりました。
「’answer’: ‘Yellowfinは、E2EのBIアプリケーションとして社内利用や、社外向けの独立したダッシュボードとして利用できるBIツールです。必要な機能だけを部品として他のアプリケーションに組み込んだり、豊富なAPIを利用することも可能です。’」
YellowfinがBIツールであることを前提とした回答になっていることに加え、製品の強みも認識した上での文章になっています。
このように、RAGやファインチューニングを使って、用途に適した回答を生成AIに作成させることができます。
最後に
深刻化する日本の人手不足に対応するために、生成AIを活用した業務効率化は各社に共通する課題と言えます。そのためには、汎用的な情報を学習したLLMだけでは不十分な場面もたくさんあるはずです。ファインチューニングやRAGを使って、各社に適した生成AIの活用法を探ってみてはいかがでしょう。
参考情報
AISmiley: https://aismiley.co.jp/
Softbankブログ: https://www.softbank.jp/biz/blog/