
Yellowfin 対 Qrvey: 違いは何か?
今日のデータドリブンな時代において、既存のアプリケーションワークフローにデータ分析を統合し、データドリブンな意思決定のための重要なインサイトをより多くの人々が得られるようにするために、ビジネスインテリジェンス (BI) や組み込みアナリティクスソリューションへの依存が益々高まっています。しかし、このような重要で長期的なビジネス目標を達成するためには、最適な価値を得るためのツールを比較する必要があります。
本ブログは、継続的な比較シリーズの一環として、最新バージョンのYellowfinとQrveyの機能セットや特徴の違いについて紹介し、組み込みアナリティクスソリューションを評価する企業が自社のニーズに最適なものを見つける支援をします。

機能や特徴におけるYellowfinとQrveyの比較概要
Yellowfin 対 Qrvey: 概要
Qrveyは、SaaSアプリケーション向け組み込みアナリティクスユースケースをターゲットとした軽量なビジネスインテリジェンスプラットフォームです。Yellowfinと同様、Qrveyは、高度にカスタマイズされた拡張可能なアナリティクスエクスペリエンスをビジネスアプリケーション内に作成して組み込み、データ分析とレポーティングを既存のアプリケーションエクスペリエンスによりシームレスに融合させることを目指す組織を対象としています。
Yellowfinとは異なり、Qrveyは、Amazon ウェブサービス (AWS) クラウド・コンピューティング・プラットフォーム上でのみ動作するサーバレスプラットフォームであり、AWS コンポーネントで構成され、アナリティクスエクスペリエンスをAWS環境にのみデプロイしたい顧客に焦点を当てています。
オンプレミスへの導入の場合、Qrveyは現時点では実行可能な選択肢ではないことも意味します。これに対してYellowfinは、複数のプロバイダー (AWS、GCP、Azure) を介してクラウドとオンプレミスの両方に導入することができます。
このため、QrveyにはYellowfinとの違いや制限がいくつかあり、限られた小規模なユースケースにしか適していません。以下では、各アナリティクスソリューションの評価に役立つように解説していきます。
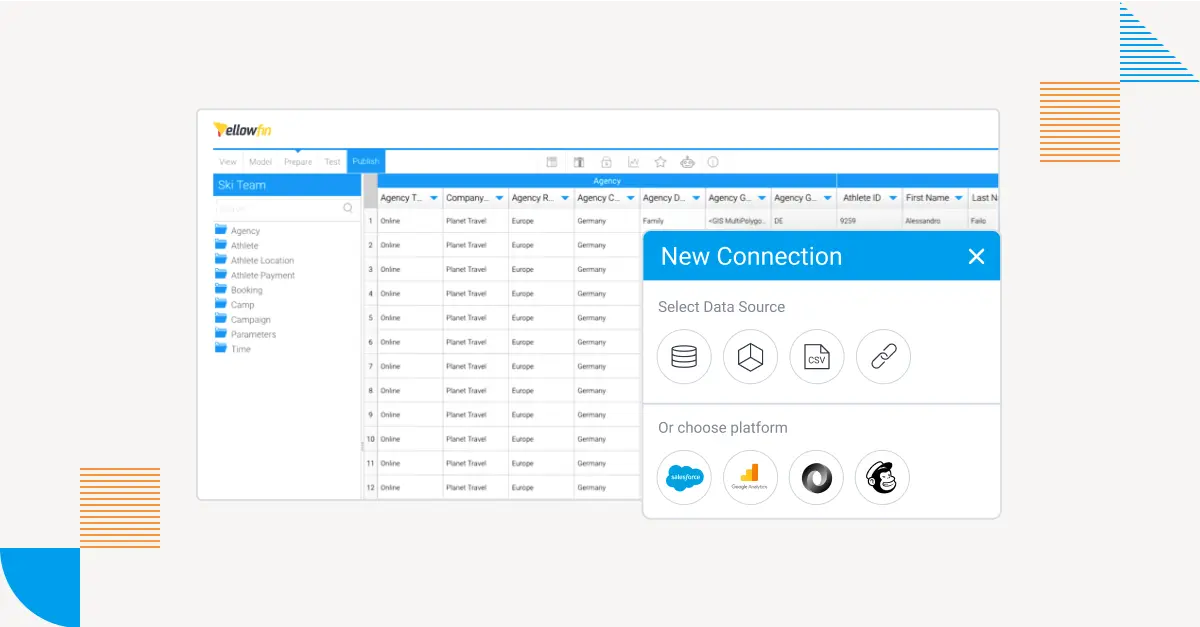
Yellowfin 対 Qrvey: データストレージおよびアクセス
他のBIプラットフォームと同様に、Qrveyはクエリーの発行やレポーティングにおいて、シンプルでキュレーションされた形式のデータに依存しています。そのため、複雑なデータセットにクエリーを発行したり、ビジネス上の質問に答える複雑なクエリーを生成したりする機能はありません。
ユーザーにはデータに関して次の2つの選択肢があります。
1. Qrvey プラットフォームにデータを取り込む – Qrveyは限られた数のデータベースプラットフォームとの接続をサポートしています。これらのプラットフォームからデータを取り込み、Qrvey内の単一テーブルにそのデータのコピーを作成することができます。データはElasticSearch データベースに保存されます。ユーザーはデータを抽出する際に簡単な結合を実行することができますが、結果のデータは単一のテーブルに保存されます。これにより、多くの課題が発生します。
- データが冗長に保存されるため、ストレージコストが重複する
- データが古くなるため、ソースから定期的に更新をする必要がある
- すべてのデータが平坦化されるため、複雑なデータ構造はサポートされない。ディメンション (次元) のバージョン管理などの概念をサポートするためには正規化が必要なため、スタースキーマなどの一般的な分析構造はサポートできない。
- データをベンダーに保存すると、そのベンダーのプラットフォームへのロックインが高まる可能性があり、切り替えをしたり、複数のツールをデータベースに接続したりするのが難しくなります。
2. Qrveyからのライブクエリー – ユーザーはAWS内で限られた数のデータベースプラットフォームにライブ接続できますが、データは単一のテーブルに限られます。結合、UNION、数式などの単純なSQL構文はサポートされません。ユーザーには手作業でSQLコーディングをするオプションがあります。
Qrveyは、データを取り込むときに適用できるカラム (列) レベルのトランスフォーメーションを限定的にサポートします。これらのトランスフォーメーションは、データが取り込まれたときのみ適用されるため、ライブクエリーモードでは使用できず、新しいトランスフォーメーションを適用したり、既存のトランスフォーメーションを変更したりした場合は、データセット全体が再読み込みされたときにのみ有効になります。
Yellowfinの主な強みの1つは、最も複雑なデータベーススキーマに対応し、高度なメタデータモデリングレイヤーを使用して非常に複雑なSQLを生成できることであり、これによりデータアナリストは、あらゆるプラットフォームで実行されている事実上あらゆるデータソースからあらゆるデータモデルをマッピングすることができます。Qrveyと比較した際に、この分野におけるYellowfinの利点は以下の通りです。
- メタデータレイヤーはモデルの複雑さをすべてカプセル化し、ビジネスユーザーからその複雑さを隠します。これはデータセットごとに一度定義され、そのデータセットに対するすべてのクエリーで再利用されます。
- 複雑な計算の作成、データ形式の定義、グループ化 (データのバケット化)、さらにはデータ内の異なる値に対するカスタムカラースキームの定義など、データをモデル化する際には膨大な数のオプションが存在します。これらのオプションはすべてクエリー発行時に適用され、データを個別に抽出して保存する必要はなく、このレイヤーの変更は次回データにクエリーが発行された時に即座に反映されます。
- Yellowfinのクエリージェネレーターは、外部結合を含むあらゆる種類の結合や、多くの種類のサブクエリーを含む最も複雑なSQLを生成することができます。実行時にまったく異なるデータベースのデータを動的に結合することも可能です。
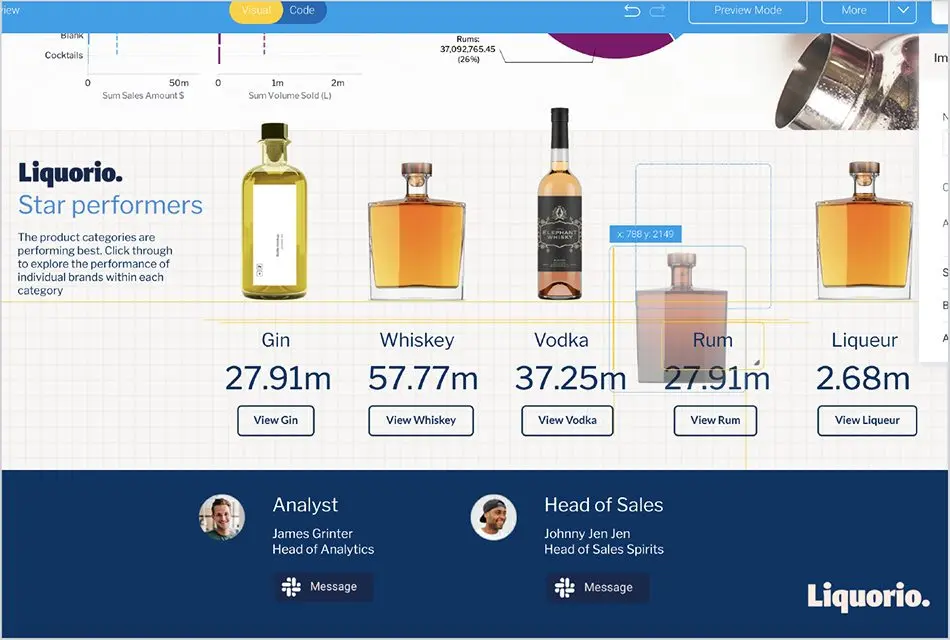
Yellowfin キャンバスとアナリティクスエクスペリエンスの例
Yellowfin 対 Qrvey: アナリティクスエクスペリエンス
Qrveyは多くのBIプラットフォームと同様、単純な表形式のレポートや様々なグラフ、シンプルなグリッド状のダッシュボードを表示することができます。ダッシュボードはグリッド状で構成され、ユーザーはサイズ変更可能な各グリッドスロットにコンテンツを追加できます。これらのコンテンツには、表、グラフ、イメージ、テキスト、ボタンなどを含めることができます。Qrveyは、レポート作成を簡素化するために、ビジュアルベースのドラッグ&ドロップ型レポートビルダーもサポートしています。
BI業界は、レポート、グラフ、ダッシュボードへの依存から脱却し、一般的なビジネスユーザーにとってより使いやすく、より魅力的な代替のプレゼンテーションメカニズムに移行しようとしています。Yellowfinでは、このようなユーザーをアナリティクスユーザーまたは拡張ユーザーと呼んでいます。このタイプのビジネスユーザーは、一般的にデータを深く理解しておらず、インサイトを発見する方法や複雑なグラフやレポートを解釈する方法を知りませんが、一般的にアナリティクスソリューションのユーザーの大半を占めています。Yellowfinではその後、以下の機能を含む、従来のレポートやグリッド状のダッシュボードに代わる製品を提供することで、これらのユーザーのニーズをよりよく満たすように製品を進化させてきました。
キャンバス – Yellowfinに搭載されている機能であるYellowfin キャンバスを使用することで、複雑で忠実度の高いデザインを作成でき、豊富なコンテンツをレイヤー化して、素晴らしい見た目のダッシュボードを作成することができます。
プレゼンテーション – Yellowfinのデータストーリーテリング機能であるプレゼントを使用して、エグゼクティブユーザー向けやライブプレゼンテーションで使用するデータドリブンなプレゼンテーションを構築できます。
ストーリー – Yellowfinのデータストーリーテリング機能であるストーリーを使用することで、データ内で何が起きているかを、データそのものだけでなく、画像やビデオなどの豊富なコンテンツとともに長文形式のナラティブとして提供することができます。
シグナル – Yellowfinの自動分析機能であるシグナルは、データの重要な変化を検出するために、すべてのデータをスキャンおよび分析する高度で完全に自動化されたビジネスモニタリングプロセスです。
NLQ (自然言語クエリ) – Yellowfin独自のNLQ機能であるガイド付きNLQは、質問を入力することでクエリを生成し、あらゆるビジネス上の質問に答える独自のガイド付きアプローチです。
これらのオプションは、アナリティクスエクスペリエンスを向上させるだけでなく、この機能を既存のビジネスアプリケーションにホワイトラベル化したり、組み込んだりする顧客に独自の優位性を提供し、アナリティクスを使用して競合と製品を大幅に差別化する能力を提供します。この戦略とそれによって生み出された能力が、GartnerがYellowfinをBIとアナリティクスのマジッククアドラントで3年連続ビジョナリー (概念先行型) として評価した理由です。
Yellowfin ストーリーとそのデータストーリーテリング機能の例
Yellowfin 対 Qrvey: 機能の深さ
Qrveyは市場で比較的新しいBI製品であるため、特定の分野では機能の深さに欠けています。その多くは、製品をしばらく使用し、他のツールで使い慣れた機能にアクセスしようとした時に、Qrveyの専用製品には今のところ存在しないことが分かって初めて分かるものです。
Yellowfinは、20年以上にわたる開発の実績があり、その組み込み製品には驚くほど豊富な機能が搭載されているため、ほとんどすべてのBI要件を満たすことができます。以下は、Qrveyにはない機能の数々です。
- Yellowfin ブロードキャストを使用したレポートやダッシュボードの高度なスケジューリングとブロードキャスト – 保存されたフィルターセットを使用してレポートやダッシュボードの配信をスケジュールし、他のレポートに基づき受信者一覧を動的に作成して、コンテンツのディスクへの保存を含む任意の形式でのブロードキャスト
- 条件付き書式、セクション、合計書式を含む、高度なレポート書式設定
- Set分析、高度な関数、その他の手法を使用した複雑な分析
- フィルターやドリルの状態を保存し、これらをデフォルトまたはブロードキャストに適用する公開および非公開ブックマークを作成する機能
- レポートデータを自動的に分析したり、レポートコンテンツを生成する自動インサイト
- ストーリーテンプレートと通常のレポート作成にストーリーを使用できるようにする機能
Yellowfin 対 Qrvey: まとめ
まとめると、Qrveyは、特定の組織、特に小規模な要件を持つ企業や、あまり高度なニーズを持たない顧客に適した選択肢となる、それなりに優れた製品を提供しています。Qrveyは、本格的なBIプラットフォームへの足がかりとなる製品です。これは非常に単純化されたデータアクセスメカニズムを持ち、シンプルなレポートやグラフ、グリッド状のダッシュボードとしてデータを表示することに限定されています。
自動化、自然言語クエリ、データストーリーテリングなどの高度な機能とともに、より深いデータビジュアライゼーションやレポート機能を備えたアナリティクスソリューションをお求めの場合にはYellowfinが最適です。
Yellowfinをご自身でお試しください
YellowfinとQrveyのソリューションにはどのような違いがあるのかを、無料デモでご確認ください。
「デモをリクエスト」
製品紹介資料はこちら↓
