 2.0について")
Data Vault(データボルト) 2.0について
はじめに
国内では、数年ほど前からData Vault(データボルト) 2.0という単語を耳にすることが増えてきました。欧州、北米の順に、Data Vault 2.0 の考え方が一般企業にも広まってきているようですが、まだまだ日本には浸透してきていません。今後日本市場にも浸透する可能性を秘めたData Vault 2.0に関して説明します。
◎製品資料をCheck!Yellowfinについて理解を深めよう↓

従来型データ構造
まずは、一般的に普及する従来型データ構造から話を始めます。
Third Normal Form (3NF)
第3正規化と呼ばれるデータベースの設計手法で、広く普及するデータベース設計です。冗長性を最小化するためにテーブルを切り出し、テーブル間にリレーションを張ることで、データの関連性を担保します。一般的にはER図を作成して設計します。

ディメンショナルモデリング:スタースキーマ
中央に位置するファクトテーブルから、周囲に位置するそれぞれのディメンションテーブルにリレーションが張られている形状です。その形状がスターに似ていることからスタースキーマと呼ばれ、DWHの設計時にはできる限りスタースキーマに近づけることが望まれます。

ディメンショナルモデリング:スノーフレークスキーマ
その名の通り、雪の結晶のようにディメンションテーブルが複数連携している形状を指します。スタースキーマ同様に、DWHの設計に一般的な手法です。スタースキーマと比較して正規化が丁寧に行われる一方、パフォーマンス面ではスタースキーマが優れます。
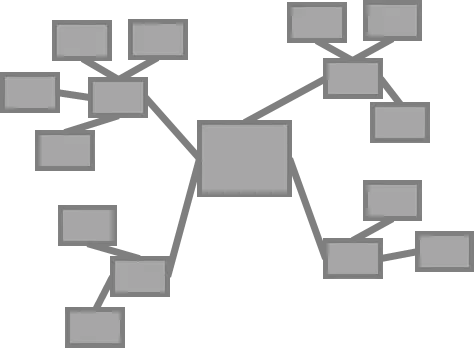
Data Vault データモデリング
ここまで従来型3NFやディメンショナルモデリングに関して説明しました。これらとは異なる Data Vaultのデータモデリングとはどのようなものなのか、順を追って説明します。
なお、Data Vaultデータモデリングの説明に際して、英国のData Vaultユーザーグループの情報を多いに参考にさせていただきました。
目的に応じたデータの切り出し
旅行の予約サイトに関わるテーブル(BOOKING)があるとします。このテーブルから、目的に応じてBOOKING DETAILS(予約詳細)、CUSTOMER(予約者)、PRODUCT(商品)、ADDRESS(住所)、FLIGHT(航空券)、TRANSACTION(取引)、ACCOMODATION(宿泊)の7テーブルを切り出します

再モデリング
目的別に切り出したテーブルの中から、必要なものを選択し、データモデルを再構築します。
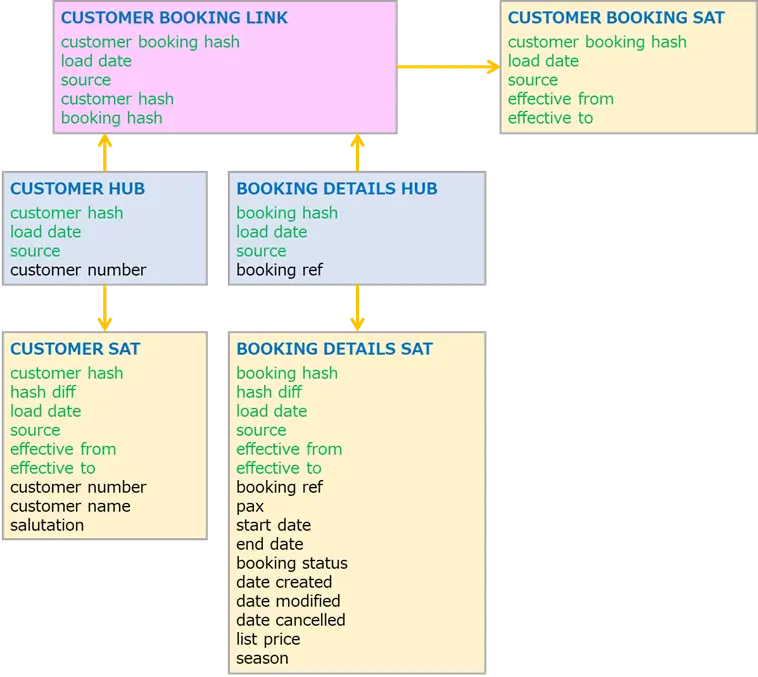
データモデル全容
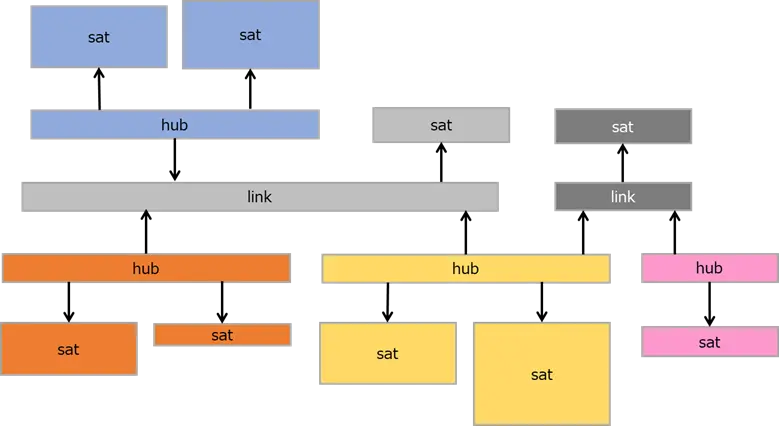
上記イメージを見ながら、データモデリングの説明を進めます。薄黄色の背景がSatellite、薄青Hub、薄桃がLinkテーブルです。各テーブル内の列に関しては、緑文字がメタデータ、黒文字が実データを指します。
Link
LinkテーブルはEntity(実体)どうしを結びつける役割で、メタデータを含むものです。実データは含みません。例えば、customer booking hushはCUSTOMER BOOKING SATとリレーションを張るために発行されたハッシュ値、load dateはデータがロードされた日時、sourceはデータソースを指します。
Hub
HubテーブルはLinkテーブルとSatelliteテーブルを結ぶ役割で、メタデータとビジネスキーを含みます。ここでいうビジネスキーとは、簡単に言えばSatelliteの主キー(自然キー)とお考え下さい。
Satellite
Satelliteテーブルは実データを含むものです。実データ以外にも、effective from/toのように、データの有効期限を適宜する情報や、行の変更にかかる処理を最適化する目的のhash diffなどのメタデータを含みます。
なお、一般的な慣習として、LinkとディメンションSatellite間にはHubを配置しますが、LinkとファクトSatellite 間にはHubを配置しないそうです。
SQL
各テーブルを作成するための SQLはシンプルで、テンプレート化しやすいものです。
例えば、Linkテーブルを作成するためのクエリーは以下のようなものです。
insert ignore into customer_booking_link (customer_booking_hash, load_date,
source, customer_hash, booking_hash)
select md5(concat(customer_number, booking_reference)),
load_date, source, md5(customer_number),
md5(booking_reference) from bookings;
タグに置き換えると以下のようになり、類似の処理への使い回しが比較的容易です。
insert ignore into <tgt_link> (<pk_hash>, load_date,
source, <fk1_hash>, <fk2_hash>)
select md5(concat(<fk1>,<fk2>)),
load_date, source, md5(<fk1>), md5(<fk2>)
from <stage_table>;
テンプレート化した処理を、関数やストアドプロシージャ化しておくことで、処理の自動化につながります。
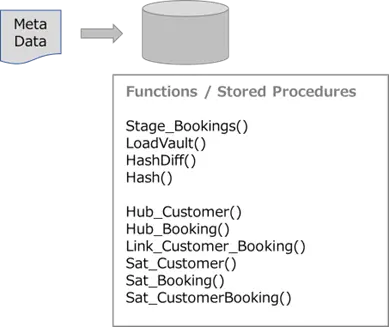
その他のアーキテクチャー
ここまで、Data Vaultデータモデリングに関して説明してきました。冒頭でも述べたように、Data Vault 2.0では、データモデリングに加え、プロセスのデザインやアジャイル開発なども考慮されます。
レイヤー
データ処理の流れに従って、プロセスのデザイン例を見てみます。下記のように、Data Lakeに蓄積されたデータを目的に応じたMartに切り出すまでの処理を順に追ってみます。
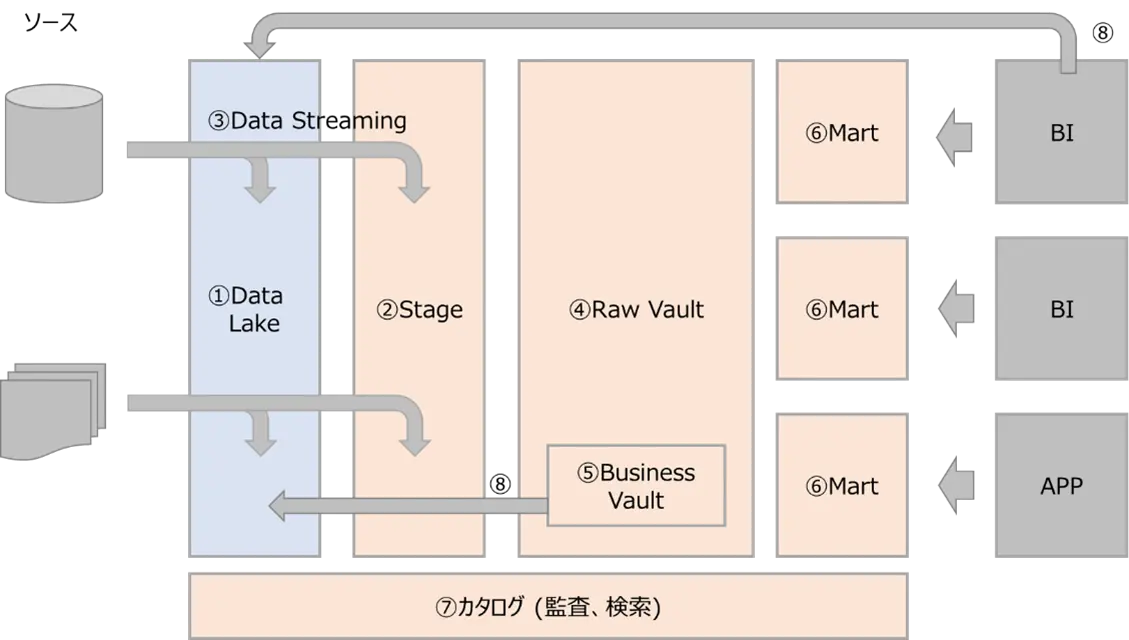
- 各種データソースから集められるデータが、Data Lakeに蓄積されます。
- Data LakeからStageにデータが移行され、Stageを介して、Data Vaultとして扱うデータに適した構造に修正します。もちろん、Data Lakeを介さず、直接 ソースからStageにコピーされるデータもあり得ます。
- 上記の流れを、Data Streamingとして管理します。
- Stagingを通じてData Vaultのデータモデルとして扱うことができるようになったら、Raw Vaultに移行します。Raw Vault領域には、Link、Hub、Satelliteなど、Data Vaultデータモデリングにひつような各種テーブルが存在します。
- ビジネスルールを適用して、新たなデータが生成されることもあります。これらデータはBusiness Vaultで管理されます。
- Raw Vault のデータは目的に応じて、Data Martとして切り出されます。
- 上記一連のデータの流れに関しては、カタログ化され、監査や検索に活用されます。
- BIが生成するデータや、Business Vaultに生成されたデータが、Data Lakeにコピーされ、再活用される動きもあるでしょう。
アジャイル開発への適用
上記レイヤーにおけるプロセスの流れを、アジャイル開発に適用してみます。
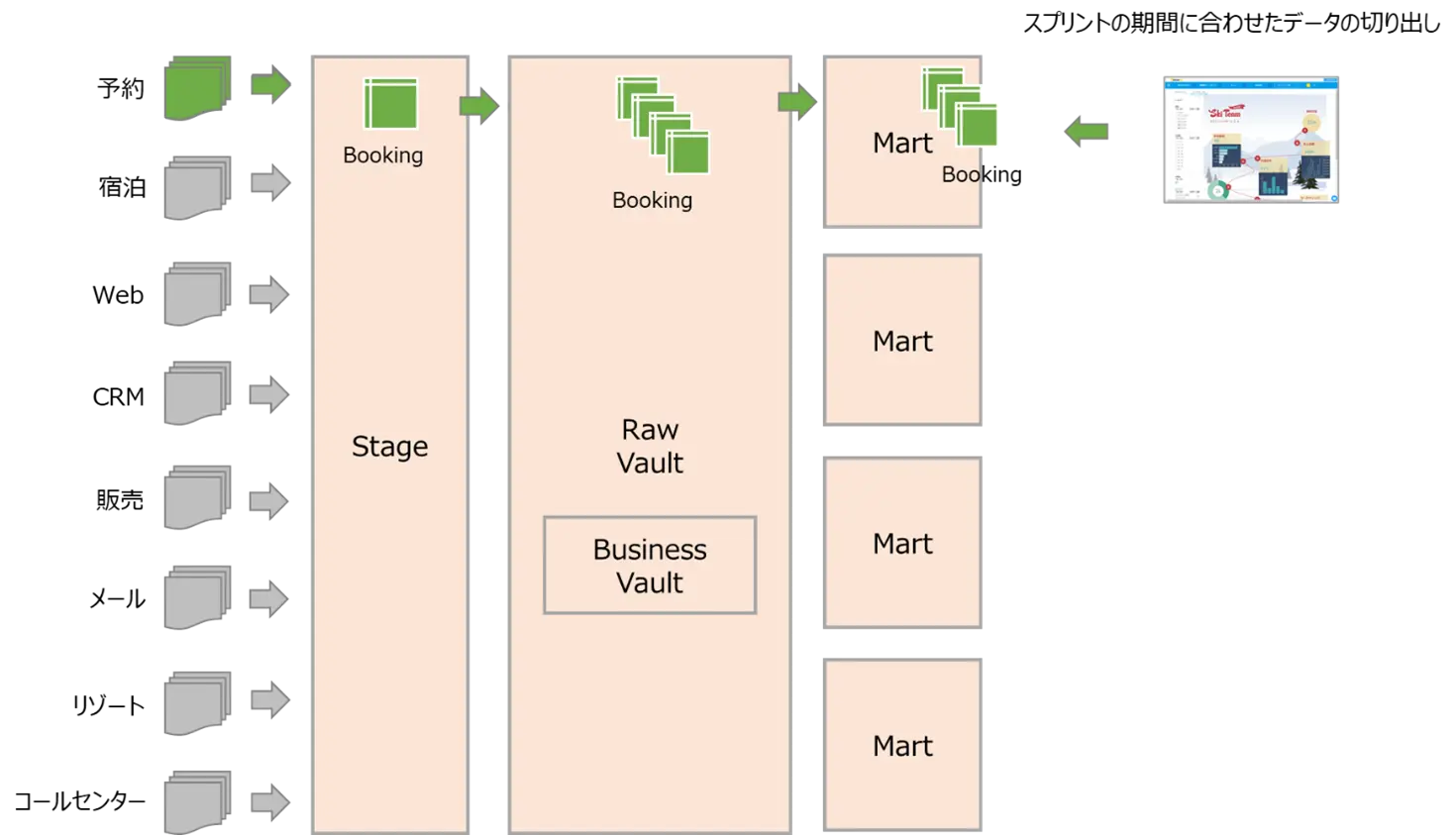
複数ダッシュボードを作成するアジャイル開発プロジェクトの中で、予約、宿泊など、目的別ダッシュボードを開発する単位でスクリプトを区切る場合、それぞれのスクリプト期間に応じたデータを切り出すことが求められます。そんな時、Raw Vaultで管理するテーブルの中から、必要なものだけを取り出して、Martに切り出すなどの手段を取ることができます。
プレゼンテーションレイヤーにおける展開例
アジャイル開発への適用例を説明しましたが、もう少しデータモデルに近い視点で考えてみます。
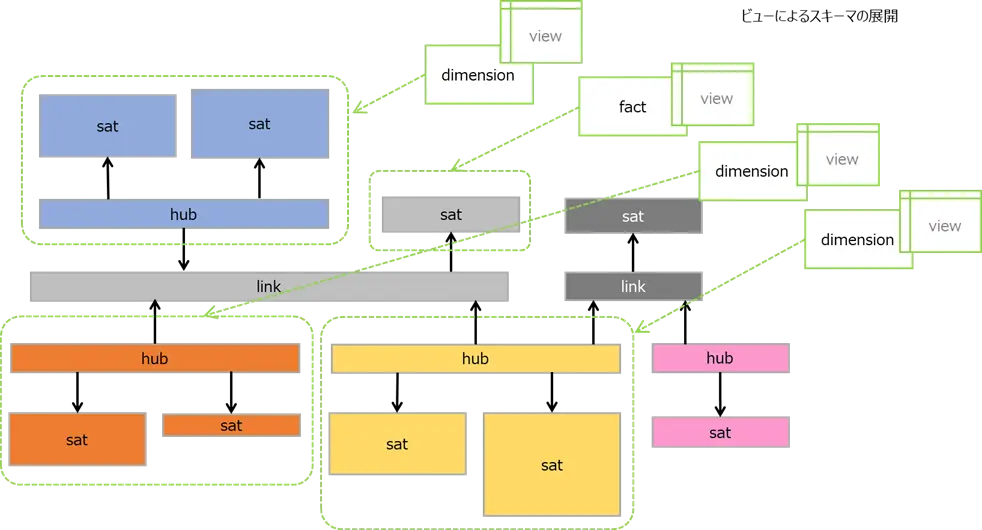
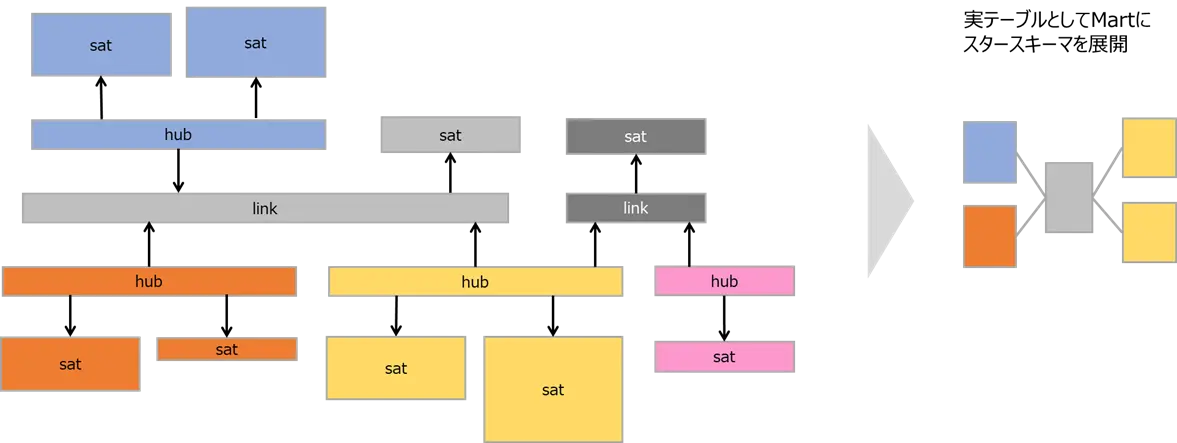
以下のようなData Vaultのモデルがあるとします。linkと直接連結されるSatelliteがファクト (薄灰、濃灰)、linkとhubを介して連結されるsatelliteがディメンション (青、橙、黄、桃) です。
このモデルを、ビューを介して展開することができます。
あるいは実テーブルとして、Data Martにスタースキーマを展開することも可能です。パフォーマンスを求める場合、実テーブルとしての展開が望まれます。
ELT との親和性
従来の ETLに代わり、ELTという考え方も浸透してきています。
『ETLとELT』 https://qiita.com/ExtremeCarvFJ/items/d4bca89792efea7332b1
Data Vaultのアーキテクチャーは、ELTとの親和性が高いため、様々なデータの処理に対して、クラウド上のデータベースのリソースを活用することが可能です。大規模なデータ処理にも対応できます。
Data Vault 2.0 の特長
最後にData Vault 2.0の特長を簡潔にまとめると、以下の3点に集約されます。
・アジャイル開発との親和性の高さ
・クラウドに情報資産を移行する中で、スモールスタートから、次第にテラバイト、ペタバイトまで拡張できる柔軟性の高さ
・監査制や追跡性に優れ、コンプライアンスの要件への対応
処理の自動化
現実的には、データモデル作成や、データ更新などの処理を自動化しないと運用が回りません。そのためには、パッケージ製品の導入などの検討を進める必要があります。
Yellowfin と同じ Idera グループ傘下の WhereScape 社が、Data Vaultに適した製品を開発・販売しています。
Wherescape:https://www.wherescape.com/
最後に
欧州では、クラウドにデータが集約される中で、伝統的な3NFに代わり、Data Vaultが主流になってきています。必ずしもコンプライアンスがけん引となっている訳ではなく、本当に優れたソリューションとして、Data Vault 2.0の考え方が市場に広まっているようです。この流れは北米にも伝達しつつあります。近い将来、日本にも広まってくることが予想されます。
最後に、Data Vault 2.0の考え方は、あくまでベストプラクティスとしての扱いです。自分たちが必要とする部分だけを取り入れることが重要です。
チャートの作成方法や本記事に関する詳しい説明を聞きたい方はお気軽にお問い合わせください。
◎製品資料をCheck!Yellowfinについて理解を深めよう↓